Como estava esse conteúdo?
- Aprenda
- Modelos mundiais e a pilha multimodal de IA: reescrevendo as regras da robótica
Modelos mundiais e a pilha multimodal de IA: reescrevendo as regras da robótica

Durante a maior parte da história da humanidade, aprendemos e entendemos o mundo por meio de nossos corpos e do tato. Aprendemos que o fogo queima ao chegar muito perto de uma chama, aprendemos que o gelo é escorregadio ao cair. Esse conhecimento foi incorporado e adquirido por meio da experiência direta e só podia se disseminar depois que uma pessoa o experimentasse, acumulasse e transmitisse.
Para transmitir e compartilhar conhecimento de maneira mais ampla, foi preciso formalizá-lo. As leis do movimento foram escritas, a termodinâmica foi codificada e os sistemas que modelam o comportamento do mundo foram desenvolvidos. Essa abordagem criou a base da física e, por três séculos, essas regras artesanais foram o único meio que tínhamos de entender o mundo.
Depois veio a revolução do machine learning e, em vez de codificar manualmente o conhecimento, os sistemas podiam ser treinados para aprendê-lo. As representações manuais foram substituídas por outras aprendidas, não para a física (ainda), mas para a linguagem. No momento em que um modelo tipo transformador treinado em texto da Internet conseguiu gerar uma prosa fluente e coerente, as regras gramaticais que os linguistas haviam passado décadas escrevendo subitamente se tornaram obsoletas. A lacuna entre a abordagem antiga, feita à mão, e a nova, de representações aprendidas, marcou uma grande mudança estrutural. Em menos de uma década, todo o castelo da PNL baseada em regras havia desmoronado.
Um grande salto para a robótica?
Atualmente, a IA robótica e IA física estão exatamente na mesma posição em que a IA linguística estava em 2005. Cada simulação é baseada em física codificada manualmente. Cada dinâmica de colisão, cada coeficiente de atrito e cada modelo de contato são especificados por engenheiros que, na verdade, estão escrevendo regras gramaticais para o mundo físico.
Um robô treinado em uma dessas simulações pode funcionar bem no ambiente para o qual foi criado. Porém, os problemas surgem quando ele vai para um ambiente desconhecido, como uma cozinha, ou quando você pede para ele executar uma nova tarefa, como pegar um objeto. Não porque a simulação tenha sido mal construída, mas devido a falhas estruturais: você não pode codificar manualmente seu caminho para a inteligência física geral, assim como não pode codificar manualmente seu caminho para o GPT-4. A física codificada manualmente não pode ser dimensionada para a inteligência física geral.
Se a IA da linguagem deu um salto tão grande, por que a robótica não pode fazer isso também? Os LLMs tinham uma vantagem significativa: a Internet. Com trilhões de tokens já digitalizados e essencialmente gratuitos, os LLMs tiveram acesso ao maior corpus de conhecimento humano já reunido. O GPT-4, por exemplo, foi treinado em cerca de 13 trilhões de tokens. A robótica não tem uma base de recursos equivalente. Cada trajetória de robô (uma instância de um robô concluindo uma tarefa) requer hardware físico, operadores humanos, ambientes reais e uma curadoria meticulosa. O conjunto de dados Open X-Embodiment, a produção combinada de 34 laboratórios de robótica em todo o mundo, contém cerca de um milhão deles. Essa lacuna, entre os 13 milhões de tokens do GPT-4 versus um milhão de trajetórias, é enorme e não pode ser eliminada com investimentos incrementais.
É necessária uma abordagem totalmente nova para aquisição de dados. E a que está surgindo, treinar robôs em vídeo na Internet, pode representar a decisão arquitetônica mais importante na história da IA física.
Modelos mundiais, conhecimento mundial e redes neurais
Um modelo mundial é uma rede neural que aprende a intuição física de maneira semelhante à dos humanos, por meio da observação, não da formalização. Como uma criança aprende que uma bola vai rolar da mesa? Não é resolvendo a segunda lei de Newton nem executando uma simulação física. Ela observa e, por fim, aprende.
Um modelo mundial funciona da mesma forma. Mostre milhões de horas de vídeos, tutoriais de culinária, chão de fábrica, tráfego, construção, e ele começará a desenvolver uma imagem interna de como o mundo se comporta. Esse tipo de entendimento implícito não é uma forma de conhecimento menos valiosa. Geralmente, é mais confiável, porque é mais flexível e se sustenta em situações que nenhum modelo codificado manualmente poderia ter previsto. Qual é a relevância disso para a robótica? Tudo se resume a uma distinção entre dois tipos de conhecimento.
O conhecimento mundial, como os exemplos de como os objetos se comportam sob a gravidade e como os materiais mudam, é universal. Não tem nada a ver com o robô específico. É a física da realidade em si e, felizmente para o desenvolvimento da robótica, a Internet está saturada de vídeos demonstrando exatamente isso.
O conhecimento da ação, como um robô específico converte comandos em movimento físico, é específico do hardware e precisa ser aprendido com dados específicos do robô. Pesquisas coletadas nos últimos dois anos apresentam um insight crucial: você precisa de muito pouco conhecimento de ação depois que adquire um forte conhecimento do mundo na base.
Vejamos dois resultados recentes que ilustram isso na prática. Primeiro, a V-JEPA 2 da Meta. O modelo mundial foi treinado em mais de um milhão de horas de vídeo na Internet e, em seguida, recebeu apenas 62 horas de vídeo de robô sem rótulo, sem treinamento específico para tarefas. Ele alcançou 80% de sucesso zero-shot em tarefas de coleta e colocação em laboratórios que nunca havia visto antes.
Em segundo lugar, o Dreamer 4 da DeepMind. O agente de IA aprendeu a coletar diamantes no jogo Minecraft, o que exigia 20 mil decisões sequenciais usando pixels brutos, sem qualquer interação ambiental. Ambos os exemplos apontam para a mesma dinâmica subjacente: a compreensão de como o mundo físico funciona pode ser alcançada usando a enorme oferta de vídeos na Internet que já existem. Os dados específicos do robô, que são escassos, só precisam cobrir o problema muito menor de como aquela máquina em particular se move. O desafio da escassez de dados que travou a robótica por anos de repente se tornou muito mais gerenciável.
Cinco arquiteturas, uma pergunta em aberto
O termo “modelo mundial” é aplicado de maneira vaga. Na prática, as principais abordagens discordam profundamente sobre o que significa representação física. Surgiram cinco arquiteturas, cada uma baseada em uma teoria diferente de como os sistemas físicos devem ser codificados em um sistema aprendido. Elas concordam que a simulação codificada manualmente é insuficiente e discordam sobre quase todo o resto.
Os modelos geradores de vídeo adotam a abordagem mais direta. Modelos como o Cosmos da NVIDIA e o GWM-1 da Runway funcionam prevendo quadros futuros, dado que uma ação específica ocorreu. Isso se baseia na ideia de que o vídeo captura informações suficientes sobre o mundo físico para treinar robôs. A desvantagem aqui é a eficiência, pois o modelo usa recursos significativos para prever cada pixel em um quadro, incluindo aqueles que são irrelevantes para a tarefa. O Genie 3 da DeepMind leva isso além. Rodando a 24 quadros por segundo, é o primeiro modelo mundial que funciona em tempo real, operando como uma simulação ao vivo e jogável.
Os modelos de espaço latente produziram alguns dos resultados mais significativos. Danijar Hafner e Timothy Lillicrap da DeepMind, por exemplo, desenvolveram a série Dreamer com base em uma ideia simples. Em vez de prever a aparência do próximo quadro de vídeo, o modelo cria um resumo interno simplificado do estado atual do mundo e o usa para simular o que acontece a seguir. Isso é muito mais eficiente e teve alguns resultados impressionantes:
- O Dreamer V2 foi o primeiro agente a alcançar um desempenho de nível humano na Atari com um modelo mundial.
- O Dreamer V3 superou os métodos especializados em mais de 150 tarefas sem nenhum ajuste específico.
- O Dreamer 4 foi treinado inteiramente com base em dados pré-gravados sem nenhuma interação em tempo real com o ambiente.
A JEPA (Joint Embedding Predictive Architecture de Yann LeCun) prevê representações abstratas, em vez de pixels. Isso se baseia na ideia de que uma compreensão abstrata e conceitual do mundo, em vez de informações visuais brutas, é mais eficaz para o raciocínio físico. A V-JEPA 2 alcançou 80% de sucesso zero-shot em tarefas de manipulação usando apenas vídeo na Internet. Yann apoia tanto essa abordagem que fundou a AMI Labs em Paris, que arrecadou USD 1,03 bilhão em uma avaliação de USD 3,5 bilhões antes de sequer enviar um único produto.
O raciocínio multimodal nativo é a ideia de que um sistema de IA precisa processar texto, imagens, vídeo e áudio juntos desde o início, não como componentes separados e então unidos. As outras quatro arquiteturas pressupõem que você pode pegar um sistema criado para texto e adicionar compreensão física a ele. O raciocínio multimodal nativo rejeita isso, argumentando que adaptar a compreensão física a um sistema que prioriza o texto cria um limite rígido sobre o que ele pode alcançar. A Elorian, cofundada por Andrew Dai e Yinfei Yang, está criando com base nessa tese. A Striker Partners liderou a rodada conjunta.
Modelos mundiais baseados em difusão podem funcionar como simuladores aprendidos de uso geral, gerando ambientes precisos inteiramente com base na dinâmica. O modelo de IA agêntica DIAMOND alcançou a maior pontuação humana normalizada entre todos os modelos mundiais no Atari 100k. O UniSim demonstrou que um único modelo baseado em difusão pode simular como humanos e robôs interagem com o mundo físico. Das cinco arquiteturas, os modelos baseados em difusão são os menos testados na robótica do mundo real.
Não está claro se um paradigma dominará ou se os cinco serão gradualmente fundidos para formar algo novo. Evidências dos últimos 18 meses sugerem hibridização. A compreensão física está surgindo em todas as cinco arquiteturas à medida que elas aumentam de escala, e a lacuna entre cada uma está diminuindo. Quando isso acontece, o maior diferencial pode não ser arquitetônico, mas, sim, qual equipe é mais rápida em transformar pesquisa em produção.
A escala está funcionando. O âmbito econômico, não.
O campo está progredindo rapidamente. Os parâmetros do modelo mundial aumentaram cerca de mil vezes em cinco anos, dos 2 milhões do PlanET aos 14 bilhões do Cosmos. Os treinamentos agora rivalizam com os maiores esforços de modelos de linguagem: o Cosmos consumiu 10 mil GPUs H100 por três meses. Nessa escala, algo interessante começa a acontecer.
A compreensão do mundo físico está começando a surgir como um efeito colateral inadvertido da escala. Os modelos não foram programados para entender causa e efeito no mundo físico, mas eles resolveram isso. A OpenAI observou isso no Sora, por exemplo, quando a consistência 3D, a permanência do objeto e a física realista surgiram como resultado das propriedades de escala no modelo. A DeepMind observou o mesmo no Genie 2 com 11 bilhões de parâmetros. Esse padrão se manteve em todas as arquiteturas, tornando difícil considerá-lo mera coincidência.
Recentemente, vários grandes concorrentes optaram por lançar seus modelos publicamente, em vez de mantê-los privados. O Cosmos da NVIDIA, a V-JEPA 2 da Meta e o pi-zero da Physical Intelligence eram todos de código aberto em 2025. Em uma área competitiva, esse é um sinal revelador, sugerindo que contribuir para uma ampla comunidade de pesquisa está se tornando uma estratégia melhor para o progresso do que mantê-los a portas fechadas.
Porém, embora a capacidade dos modelos tenha melhorado, o custo de operá-los não melhorou. Um modelo de linguagem de texto custa aproximadamente quinze centavos por cem horas de usuário. O Sora custa USD 468 por hora de usuário. Até mesmo o Odyssey, entre as opções mais eficientes, ainda requer um H100 dedicado por sessão a USD 50 por hora. O motivo é estrutural, pois o vídeo precisa ser gerado continuamente, em tempo real, quadro a quadro. Você não pode distribuir 50 usuários em uma só GPU da mesma forma que os modelos de texto, o que significa que a economia da unidade está mais próxima do preço da computação em nuvem premium do que da API.
Essa lacuna, entre o que os modelos podem fazer na pesquisa e quanto custa executá-los, é o maior obstáculo entre os resultados do laboratório e a implantação no mundo real. A boa notícia? Já vimos esse tipo de curva de custo antes. Os custos de inferência do LLM caíram aproximadamente mil vezes em três anos, e a Decart já alega uma redução de 400 vezes no custo de vídeo por meio de um mecanismo personalizado. Os sistemas de inferência de nível de produção que fornecerão isso em grande escala ainda não existem como produtos comerciais. Assim, as equipes que forem as primeiras a construí-las terão uma forte vantagem competitiva.
A NVIDIA montou a pilha de infraestrutura mais verticalmente integrada neste espaço: Cosmos para treinamento de modelos mundiais, Isaac Sim para simulação de física, GR00T para modelos de bases humanoides, Omniverse para gêmeos digitais e Jetson Thor para inferência de VLA de ponta. A AWS fornece a camada de nuvem na qual tudo isso é treinado e implantado: Amazon SageMaker para treinamento de modelos, AWS Batch para simulação em grande escala e orquestração de workloads, AWS Inferentia para inferência otimizada e AWS IoT Greengrass para gerenciamento de frota de borda. Na produção, o padrão é consistente: NVIDIA para fidelidade física, nuvem para treinamento e orquestração de dados, chip desenvolvido especificamente para implantação em tempo real.
Três lacunas que determinam os cronogramas
O desafio da infraestrutura não é a única barreira entre a pesquisa e a implantação comercial. Há três lacunas estruturais mais profundas que determinarão a rapidez dessa transição.
1. A lacuna de dados
A primeira é uma lacuna que nenhuma quantidade de vídeo consegue fechar. O vídeo captura a aparência das coisas, não como elas se sentem. Tarefas que envolvem toque, como manusear materiais, inserir componentes ou montar peças, resultam em uma queda no desempenho do modelo de impressionante para inútil. Por quê? Não há informações táteis nos dados de treinamento. Considere que uma mão humana contém 17 mil receptores de toque. A maioria das mãos de robôs implantadas, por outro lado, não tem sensores táteis. Apesar dos próprios sensores estarem disponíveis, atualmente não existe um conjunto de dados táteis padronizado em grande escala. Isso não é uma falha de financiamento ou tecnologia, mas de coordenação. Todo laboratório se beneficiaria desse conjunto de dados, mas nenhum tem incentivo suficiente para criá-lo sozinho. Quem resolve esse problema de coordenação, seja por meio de um consórcio aberto ou de um jogo de dados comercial, acelera todo o campo em uma magnitude enorme.
2. A lacuna arquitetônica
Atualmente, a maioria das empresas de robótica confia no aprendizado por imitação: demonstre uma tarefa, faça com que o robô a replique. Isso funciona para tarefas simples, mas enfrenta dificuldades em condições imprevisíveis. Quando o GRASP Lab da UPenn testou robôs treinados dessa forma em condições genuinamente novas, registrou uma taxa de sucesso de apenas 16,7%, o que está muito longe da confiabilidade exigida pelas condições do mundo real.
Os modelos mundiais oferecem uma abordagem diferente. Um robô pode explorar os modos de falha na simulação, iterar em casos extremos sem risco físico e desenvolver competência antes da implantação no mundo real. Cada caso documentado de um robô operando continuamente por 10 horas ou mais sem intervenção humana usou esse aprendizado por reforço, não por imitação. Para alcançar a confiabilidade em nível industrial, precisamos ir além da simples imitação para métodos de aprendizado mais robustos.
3. Coerência temporal
Modelos mundiais geradores de vídeo podem simular uma física convincente em curtos períodos. Estendidos em períodos mais longos, eles começam a se tornar inconsistentes. Os objetos podem acabar no lugar errado ou algo que deveria causar uma reação, não causa. Quanto mais a simulação for executada, mais erros podem se acumular, até que o mundo simulado não se pareça mais com o físico. O Genie 3, por exemplo, é coerente por apenas alguns minutos antes que esse tipo de desvio se instale. É um problema que está embutido na forma como esses modelos são projetados, portanto, requer uma solução arquitetônica. Outros modelos, como o Marble da World Labs, conseguem lidar melhor com o desvio temporal, mas tendem a ser mais caros. O verdadeiro desafio, portanto, está em encontrar o equilíbrio certo entre simulações de alta fidelidade e o custo de executá-las.
Mapeamento do ecossistema
Mapeamos mais de 120 entidades em todo o ecossistema de IA multimodal e modelos mundiais. A visualização completa da rede interativa está incluída neste documento.
Muitas das pessoas por trás dessas empresas são pesquisadores, não gerentes de produto, e deixaram o campo acadêmico para se juntar a grandes marcas de tecnologia. Hafner e Yan passaram da série Dreamer para Embo, Hausman deixou a equipe de robótica da DeepMind para cofundar a Physical Intelligence, LeCun passou da Meta AI para a AMI Labs.
A disposição desses pesquisadores de deixar suas funções permanentes e laboratórios de pesquisa corporativos para comercializar a ciência que estão desenvolvendo sinaliza uma grande mudança. A ciência básica amadureceu além do ponto em que o retorno do próximo artigo excede o retorno do primeiro produto.
Quem captura valor e com que rapidez?
Todas as grandes transições no machine learning seguiram o mesmo padrão, tão consistente que se assemelha mais a uma lei natural do que a uma tendência. As representações aprendidas substituem as desenvolvidas à mão. Toda vez que a IA encontra um modo de aprender algo automaticamente com os dados, ela substitui a antiga abordagem de humanos codificarem manualmente as regras, e isso acontece rapidamente. Os transformadores fizeram isso com regras gramaticais codificadas manualmente, e os modelos mundiais agora estão tentando o mesmo com a própria física, substituindo simuladores feitos à mão por modelos aprendidos treinados em vídeo em escala de Internet.
A questão agora não é se isso acontece em princípio, mas com que rapidez acontece, quais desafios são resolvidos primeiro e quem captura valor duradouro.
O dimensionamento é claro e consistente em todas as arquiteturas, e a economia de dados está melhorando. Os custos de inferência ainda são altos, mas estão caindo, devido a uma combinação de projetos de modelos mais eficientes, melhor infraestrutura de atendimento e rápida implantação de hardware de inferência especializado.
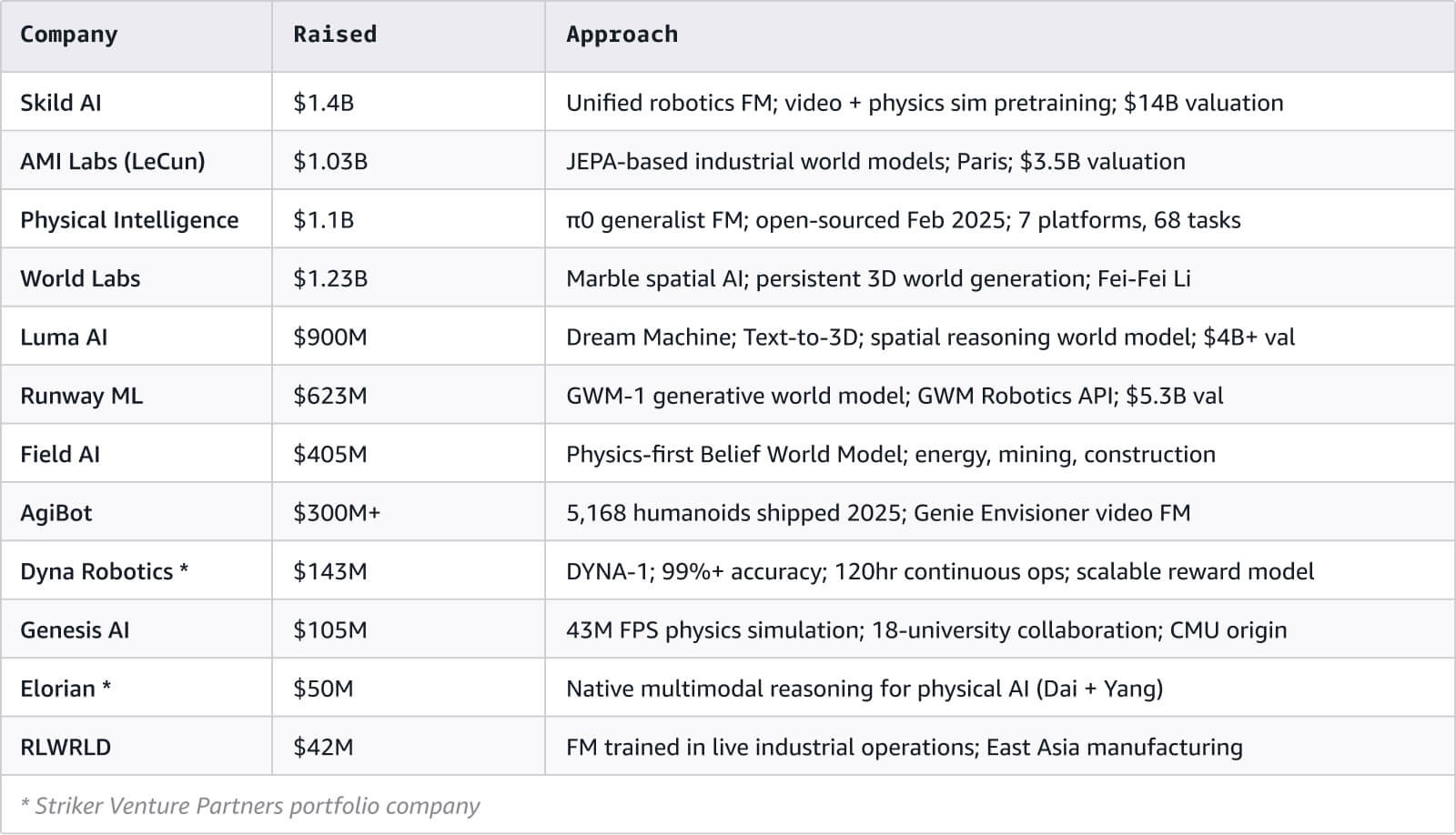
Há também uma riqueza de capital apoiando o mercado: mais de USD 3 bilhões foram obtidos nas principais startups de modelos de fundação, e as empresas que criam hardware humanoide são, no total, avaliadas em mais de USD 50 bilhões.
A camada mais importante e menos desenvolvida é a infraestrutura que conecta modelos treinados a implantações no mundo real: as ferramentas, os mecanismos de serviço e os sistemas de gerenciamento de frotas. As empresas e os fundadores que criam essas soluções ocuparão a mesma posição que os provedores de nuvem como a AWS ocupam no mundo dos modelos de linguagem: fornecendo a camada crítica da qual, em última análise, todo o resto depende.

Nikhil Suresh
Nikhil Suresh é investidor na Striker Venture Partners, onde faz parcerias com fundadores desde o início para criar empresas que definem categorias em IA, infraestrutura e hardware. Ex-fundador em série e pesquisador de IA no Scaling Intelligence Lab de Stanford, Nikhil foi um dos primeiros engenheiros da Mercor a trabalhar em Pesquisa e ML. Nikhil se concentra em ajudar equipes de alto potencial a lidar com a formação de produtos em estágio inicial para criar negócios geracionais duráveis.

Dhruv Sharma
Dhruv Sharma faz parte da equipe de capital de risco e startups da AWS, onde faz parcerias com as principais empresas de capital de risco e suas empresas de portfólio para criar, lançar e escalar, especialmente em infraestrutura de IA e tecnologias de ponta. Anteriormente, ele passou mais de oito anos no setor de capital de risco e banco de investimento, liderando investimentos e ajudando a escalar empresas desde o estágio inicial até a IPO.
Como estava esse conteúdo?