¿Qué le pareció este contenido?
- Aprender
- Los modelos del mundo y la pila de IA multimodal: reescritura de las reglas de la robótica
Los modelos del mundo y la pila de IA multimodal: reescritura de las reglas de la robótica

En la historia de la humanidad, hemos descubierto el mundo a través de nuestros cuerpos y el tacto. Aprendimos que nos quemamos cuando nos acercamos a una llama o que nos caemos cuando el hielo es resbaladizo. Estos conocimientos se adquirieron a través de la experiencia directa y se difundían rápidamente cuando una persona lo sentía, acumulaba y transmitía.
Pero para difundir y compartir esos conocimientos, tuvimos que formalizarlos. Se escribieron las leyes del movimiento, se codificó la termodinámica y se desarrollaron sistemas que modelaban el comportamiento del mundo. Este planteamiento creó las bases de la física y, por tres siglos, las reglas definidas manualmente fueron el único medio que teníamos para entender el mundo.
Luego llegó la revolución del machine learning y, en vez de codificar el conocimiento de manera manual, se tuvieron que entrenar los sistemas para que lo aprendieran. Las representaciones manuales fueron sustituidas por otras que se aprendieron, no para la física (aún), sino para el lenguaje. El día en que un modelo de transformador basado en textos de Internet pudo generar una prosa fluida y coherente, las reglas gramaticales que los lingüistas llevaban décadas escribiendo pasaron a ser obsoletas. La diferencia entre el enfoque antiguo y el nuevo (basado en representaciones aprendidas) marcó un importante cambio estructural. En menos de una década, se había derrumbado el procesamiento de lenguaje natural basado en reglas.
¿Un gran salto para la robótica?
Hoy en día, la robótica y la IA física se encuentran en la misma posición en la que se encontraba la IA del lenguaje en 2005. Toda simulación se basa en la física programada manualmente. De hecho, el equipo de ingeniería redacta las reglas gramaticales para el mundo físico y especifica cada dinámica de colisión, cada coeficiente de fricción y cada modelo de contacto.
Es posible que un robot entrenado en una de estas simulaciones funcione bien en el entorno para el que fue creado. Sin embargo, surgen problemas si se lleva a un entorno desconocido, como una cocina, o si se le pide que realice una nueva tarea, como agarrar un objeto. No porque la simulación estuviera mal desarrollada, sino por fallos estructurales. La programación manual no permite alcanzar una inteligencia física general, del mismo modo que tampoco permitiría llegar a GPT-4. La física programada manualmente no puede adaptarse a la inteligencia física general.
Si la IA del lenguaje logró un gran avance, ¿por qué no lo puede lograr la robótica? Internet fue una importante ventaja para los LLM. Con billones de tokens, ya digitalizados y prácticamente gratuitos, los LLM tenían acceso al mayor corpus de conocimiento humano de todos los tiempos. Por ejemplo, GPT-4 utilizó alrededor de 13 billones de tokens. Sin embargo, la robótica no tiene una base de recursos equivalente. Cada trayectoria de un robot (instancia en la que un robot completa una tarea) requiere hardware físico, operadores humanos, entornos reales y una cuidadosa selección. El conjunto de datos Open X-Embodiment (el resultado combinado de treinta y cuatro laboratorios de robótica de todo el mundo) contiene alrededor de un millón de ellos. La diferencia entre los 13 millones de tokens de GPT-4 y el millón de trayectorias es grande y no se puede cerrar con una creciente inversión.
Para ello, se necesita un enfoque nuevo para la adquisición de datos. El entrenamiento de robots con videos de Internet está surgiendo y representaría la decisión arquitectónica más importante de la historia de la IA física.
Modelos del mundo, conocimiento del mundo y redes neuronales
El modelo del mundo es una red neuronal que aprende la intuición física de manera similar a como lo hacen los humanos: a través de la observación y no de la formalización. ¿Cómo aprende un niño que una pelota se cae de la mesa? No resolviendo la segunda ley de Newton ni realizando una simulación física, sino que observando y aprendiendo.
El modelo del mundo funciona de la misma forma. A través de millones de horas de video, tutoriales de cocina, fábricas, tráfico y construcción empezará a formarse una imagen interna del comportamiento del mundo. Este tipo de comprensión implícita no es una forma de conocimiento menos valiosa. Suele ser más fiable, ya que es flexible y funciona bien incluso en situaciones que ningún modelo programado manualmente podría haber anticipado. ¿Y para qué sirve esto en la robótica? Todo se debe a una distinción entre dos tipos de conocimiento.
El conocimiento del mundo, como el comportamiento de los objetos bajo la gravedad y el cambio de los materiales, es universal. No tiene nada que ver con un robot específico. Es la física de la realidad misma y, afortunadamente para el desarrollo de la robótica, Internet está repleto de videos que lo demuestran exactamente.
El conocimiento de la acción (la forma en que un robot específico traduce los comandos en movimiento físico) es específico del hardware y debe aprenderse a partir de los datos específicos del robot. La investigación reunida en los últimos dos años ha revelado una idea fundamental: se necesitan muy pocos conocimientos prácticos cuando se cuenta con un conocimiento sólido del mundo.
Veamos dos nuevos resultados que aclaran esta idea concretamente. En primer lugar, V-JEPA 2 de Meta. El modelo del mundo se entrenó con más de un millón de horas de videos de Internet, con solo 62 horas de video sin etiquetar y sin entrenamiento específico para tareas. Alcanzó un 80 % de éxito en tareas tipo pick and place, sin entrenamiento previo y en laboratorios no vistos previamente.
En segundo lugar, Dreamer 4 de DeepMind. El agente de IA aprendió a recolectar diamantes en el juego Minecraft, que requería 20 000 decisiones secuenciales a partir de píxeles sin procesar y sin ningún tipo de interacción ambiental. Ambos ejemplos apuntan a la misma dinámica subyacente: el funcionamiento del mundo físico puede comprenderse a partir de la gran cantidad de videos disponibles. Los datos específicos y escasos de los robots solo necesitan abordar el pequeño problema de cómo se mueve esa máquina. De repente, el desafío de la escasez de datos que ha frenado a la robótica durante años es ahora mucho más razonable.
Cinco arquitecturas, una incógnita
El término “modelo del mundo” se utiliza de manera poco precisa. Los principales enfoques están en total desacuerdo sobre el significado de la representación física. De hecho, han surgido cinco arquitecturas, cada una basada en una teoría diferente sobre cómo deben codificarse los sistemas físicos en un sistema aprendido. Sin embargo, concuerdan que la simulación programada manualmente es insuficiente.
Los modelos generativos de video adoptan el enfoque más directo. Modelos como Cosmos de NVIDIA y GWM-1 de Runway funcionan prediciendo los fotogramas futuros, siempre que se haya producido una acción específica. Se fundamentan en la idea de que el video contiene suficiente información sobre el mundo físico para entrenar robots. El inconveniente es la eficiencia, ya que el modelo utiliza recursos fundamentales para predecir cada píxel de un fotograma, incluso aquellos que son irrelevantes para la tarea. Genie 3 de DeepMind va un paso más adelante. Es el primer modelo del mundo que actúa en tiempo real, con una velocidad de 24 fotogramas por segundo, y funciona como una simulación reproducible en tiempo real.
Los modelos de espacio latente han generado algunos de los resultados más importantes. Por ejemplo, Danijar Hafner y Timothy Lillicrap de DeepMind desarrollaron la serie Dreamer en torno a una simple idea. En vez de predecir el aspecto que tendrá el siguiente fotograma de video, el modelo crea un resumen interno simplificado del estado actual del mundo y lo utiliza para simular lo que sucederá después. Esta acción es mucho más eficiente y ha dado magníficos resultados:
- Dreamer V2 fue el primer agente en alcanzar un rendimiento a nivel humano en Atari a través de un modelo del mundo.
- Dreamer V3 superó a los métodos especializados en más de 150 tareas sin ningún ajuste específico para cada una.
- Dreamer 4 se entrenó completamente a partir de datos pregrabados, sin ninguna interacción con el entorno en tiempo real.
JEPA (Joint Embedding Predictive Architecture de Yann LeCun) predice representaciones abstractas en lugar de trabajar a nivel de píxeles. Se basa en la idea de que una comprensión abstracta y conceptual del mundo es más eficaz para el razonamiento físico que una información visual sin procesar. V-JEPA 2 alcanzó un 80 % de éxito en tareas de manipulación, sin entrenamiento previo y solo utilizando videos de Internet. LeCun respalda este enfoque hasta tal punto que fundó AMI Labs en París y recaudó 1030 millones de USD con una valoración de 3500 millones de USD, incluso antes de que se hubiera comercializado un solo producto.
El razonamiento multimodal nativo es la idea de que un sistema de IA necesita procesar texto, imágenes, video y audio juntos desde el inicio, y no como componentes separados que están unidos. Las otras cuatro arquitecturas aseguran que se puede agregar conocimiento físico a un sistema creado para texto. El razonamiento multimodal nativo rechaza esta hipótesis y sostiene que integrar conocimiento físico en sistemas centrados para texto impone un límite a lo que pueden llegar a lograr. Elorian, cofundada por Andrew Dai y Yinfei Yang, se basa en esta tesis. Striker Partners lideró la ronda de financiación inicial.
Los modelos del mundo basados en la difusión pueden funcionar como simuladores aprendidos de uso general, lo cual genera entornos precisos a partir de la dinámica. El modelo de IA agencial DIAMOND obtuvo la puntuación normalizada más alta respecto al rendimiento humano entre los modelos del entorno en Atari 100k. UniSim demostró que un único modelo basado en la difusión puede simular la forma en que los humanos y robots interactúan con el mundo físico. De las cinco arquitecturas, ese último modelo es el que menos se ha probado en la robótica.
No está claro si un paradigma dominará o si los cinco se fusionarán paulatinamente en algo nuevo. Pero la evidencia de los últimos 18 meses sugiere la hibridación. El conocimiento físico está surgiendo en las cinco arquitecturas a medida que escalan, y la distancia entre ellas se está reduciendo. En ese momento, el principal factor diferencial puede no ser la arquitectura, sino qué equipo logra llevar la investigación a producción más rápido.
La escalabilidad funciona, pero la economía no.
El campo avanza a gran velocidad. Los parámetros del modelo del mundo se han multiplicado aproximadamente por mil en cinco años, desde los 2 millones de PlaNeT hasta los 14 000 millones de Cosmos. Ahora, las sesiones de entrenamiento compiten con las iniciativas más importantes en materia de modelos de lenguaje. Cosmos consumió 10 000 GPU H100 por tres meses. A esta escala, algo interesante empieza a suceder.
La comprensión del mundo físico comienza a surgir como un efecto secundario inesperado de la escala. Los modelos se programaron para desarrollar la relación causal del mundo físico y no para entenderlo. Por ejemplo, OpenAI lo observó en Sora cuando la consistencia tridimensional, la permanencia de los objetos y la física realista fueron resultado de las propiedades del desescalado horizontal del modelo. DeepMind observó lo mismo en Genie 2 con 11 000 millones de parámetros. Y el mismo patrón se mantuvo en todas las arquitecturas, por lo que es difícil considerarlo una simple coincidencia.
Diversos actores clave han empezado a publicar sus modelos en vez de mantenerlos como privados. Cosmos de NVIDIA, V-JEPA 2 de Meta y pi-zero de Physical Intelligence eran todos de código abierto en 2025. En un entorno competitivo, esto es una clara señal de que contribuir a una comunidad de investigación amplia se está convirtiendo en una estrategia más efectiva que mantenerlos cerrados.
Sin embargo, si bien la capacidad de los modelos ha mejorado, el costo de su funcionamiento no. Un modelo de lenguaje cuesta aproximadamente 0,15 USD por cada 100 horas de uso. Sora cuesta 468 USD por uso. Incluso Odyssey, una de las opciones más eficientes, sigue necesitando un H100 por sesión a 50 USD por hora. La razón es estructural, ya que el video tiene que generarse de forma continua, en tiempo real y cuadro por cuadro. No se pueden atender 50 usuarios en una sola GPU como lo hacen los modelos de texto, por lo tanto, los costos unitarios se asemejan más al cómputo en la nube de alto rendimiento que a los precios de la API.
La diferencia entre la capacidad de los modelos en investigación y su costo de ejecución es el principal obstáculo para llevarlos del laboratorio al uso real. Lo bueno es que ya hemos visto este tipo de curva de costos. Los costos de inferencia del LLM se redujeron aproximadamente mil veces en tres años, y Decart ya afirma haber reducido 400 veces los costos de video gracias a un motor personalizado. Actualmente, no existen productos comerciales que funcionen como sistemas de inferencia a nivel de producción que sean capaces de ofrecer esta información a gran escala. Por lo tanto, los equipos que sean los primeros en crearlos obtendrán una fuerte ventaja competitiva.
NVIDIA ha creado para ese entorno la infraestructura más integrada de forma vertical: Cosmos para el entrenamiento del modelo del mundo, Isaac Sim para la simulación física, GR00T para los modelos de bases humanoides, Omniverse para los gemelos digitales y Jetson Thor para la inferencia de VLA de periferia. AWS ofrece la capa de nube en la que se entrena e implementa todo esto: Amazon SageMaker para el entrenamiento del modelo, AWS Batch para la simulación a gran escala y la orquestación de cargas de trabajo, AWS Inferentia para la inferencia optimizada y AWS IoT Greengrass para la administración de flotas de periferia. En producción, el patrón es constante: NVIDIA para lograr alta fidelidad física, la nube para el entrenamiento y la orquestación de datos, y hardware especializado para la implementación en tiempo real.
Tres factores que determinan los tiempos
El desafío de la infraestructura no es lo único que separa la investigación de la implementación comercial. Existen tres brechas más profundas, de carácter estructural, que determinarán la velocidad de esta transición.
1. La brecha de datos
Es una brecha que ninguna cantidad de video puede cerrar. El video capta cómo se ven las cosas, no cómo se sienten. Las tareas que implican el tacto, como manipular materiales, insertar componentes o ensamblar piezas, hacen que el rendimiento del modelo sea inutilizable. Esto se debe a que no hay información táctil en los datos de entrenamiento. La mano humana contiene 17 000 receptores táctiles, en cambio, la mayoría de las manos robóticas implementadas no tienen sensores táctiles. A pesar de la disponibilidad de los sensores, actualmente no existe un conjunto de datos táctiles estandarizados a escala. No es una falta de financiación o de tecnología, sino más bien una falta de coordinación. Todos los laboratorios cuentan con un conjunto de datos de este tipo, pero ninguno tiene incentivos suficientes para crearlo por sí solo. La persona que resuelva este problema de coordinación (mediante un consorcio abierto o una estrategia comercial basada en datos) impulsará todo el campo a un nivel difícil de exagerar.
2. La brecha arquitectónica
La mayoría de las empresas de robótica confían en el aprendizaje por imitación: mostrar una tarea y hacer que el robot la repita. Esto funciona para tareas sencillas, pero es difícil en condiciones impredecibles. Cuando el GRASP Lab de la Universidad de Pensilvania probó robots entrenados de forma novedosa, registró una tasa de éxito de solo el 16,7 %, lo que está muy lejos de la fiabilidad que exigen las condiciones actuales.
Los modelos del mundo presentan un enfoque diferente. Un robot puede explorar los modos de falla en la simulación, analizar casos extremos sin riesgo físico y mejorar sus competencias antes de implementarse en el mundo real. Todos los casos documentados de robots que han funcionado de forma continua por 10 horas o más sin intervención humana han utilizado este aprendizaje por refuerzo, no por imitación. Para lograr una fiabilidad de nivel industrial, necesitamos ir más allá de la simple imitación y adoptar métodos de aprendizaje más sólidos.
3. Coherencia temporal
Los modelos del mundo generativos por video pueden simular una física convincente durante periodos cortos. Si se extienden en periodos largos se vuelven inconsistentes y los objetos pueden terminar en el lugar equivocado o impedir que haya una reacción. Cuanto más se prolongue la simulación, más errores se acumularán, hasta que el mundo simulado deje de parecerse al físico. Por ejemplo, Genie 3 es coherente solo por unos minutos antes de que se produzca este tipo de deriva. Es un problema que se basa en la forma en que se diseñan estos modelos, por lo que requiere una solución arquitectónica. Otros modelos, como Marble de World Labs, gestionan mejor la deriva temporal, aunque suelen ser más caros. Por lo tanto, el verdadero desafío yace en encontrar el equilibrio adecuado entre las simulaciones de alta fidelidad y el costo de ejecutarlas.
Análisis del ecosistema
Analizamos más de 120 entidades de los modelos del mundo y del ecosistema de la IA multimodal. La visualización interactiva de la red se incluye junto con este documento.
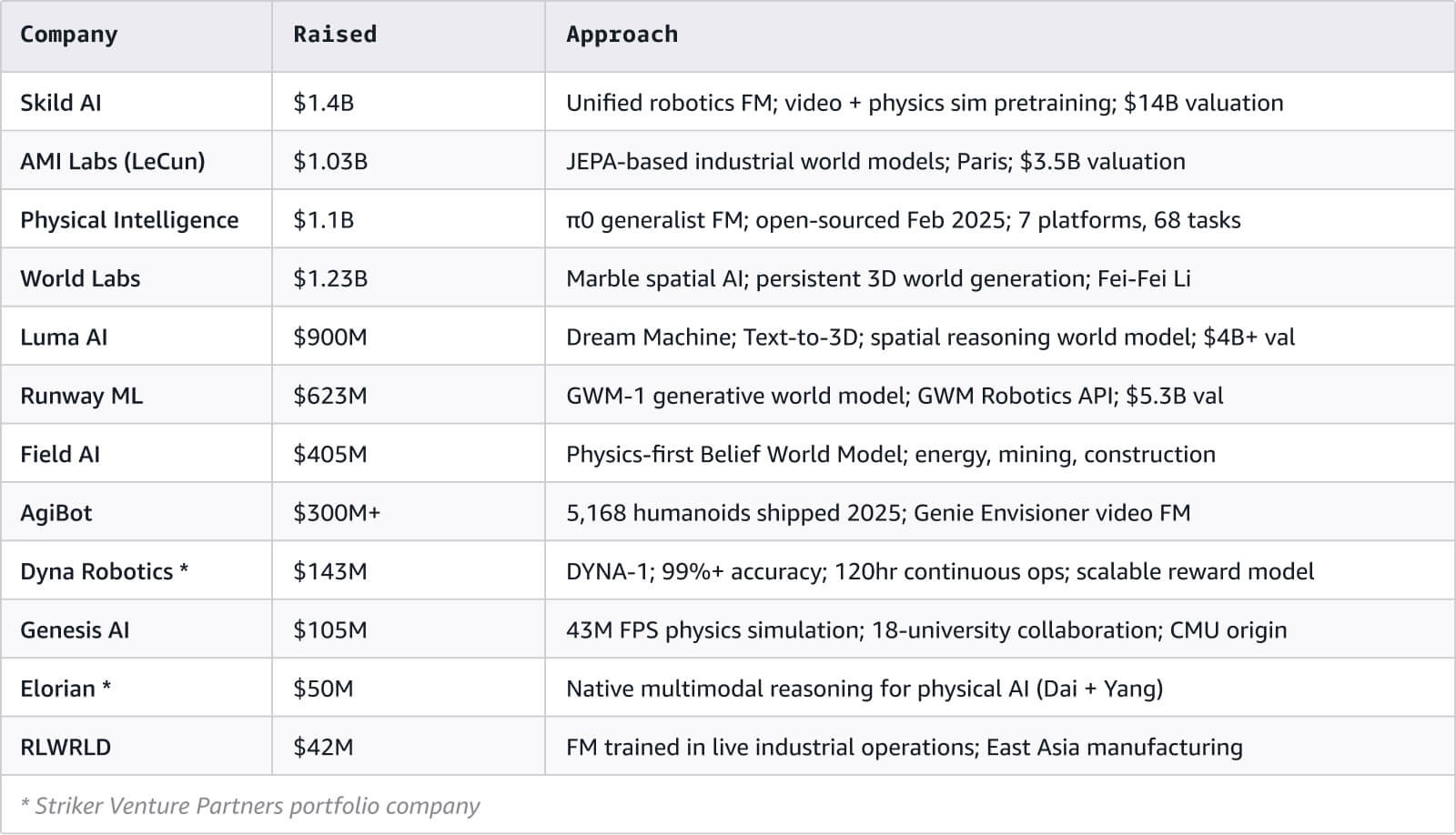
La mayoría de las personas detrás de estas empresas son parte del equipo de investigación y no de la gerencia de producto, y han abandonado el campo académico para unirse a las grandes marcas tecnológicas. Hafner y Yan pasaron de la serie Dreamer a Embo, Hausman dejó el equipo de robótica de DeepMind para cofundar Physical Intelligence, y LeCun pasó de Meta AI a AMI Labs.
El hecho de que estos investigadores dejen sus puestos fijos y los laboratorios corporativos para comercializar la ciencia demuestra un cambio relevante. La ciencia básica ha madurado más allá del límite en que el rendimiento del siguiente artículo supera el rendimiento del primer producto.
Velocidad y captura de valor
Todos los cambios importantes en el machine learning han seguido el mismo patrón, uno tan consistente que se parece más a una ley natural que a una tendencia. Las representaciones aprendidas sustituyen a las basadas en diseño manual. Cada vez que la IA aprende algo automáticamente a partir de datos, sustituye el enfoque tradicional basado en reglas codificadas manualmente. Y el cambio se está acelerando. Los transformadores ya sustituyeron las reglas gramaticales codificadas manualmente, y ahora los modelos del entorno buscan hacer lo mismo con la física, reemplazando los simuladores tradicionales por modelos aprendidos y entrenados con video a escala de Internet.
La incógnita ahora no es si ocurre en teoría, sino con qué rapidez ocurre, qué desafíos se resuelven primero y quién capta el valor duradero.
El escalado es claro y uniforme en todas las arquitecturas, y la economía de los datos está mejorando. Aunque los costos de inferencia siguen siendo elevados, están disminuyendo gracias a modelos más eficientes, mejor infraestructura de servicio y hardware de inferencia especializado.
También existe una gran cantidad de capital que sustenta el mercado: se han recaudado más de 3000 millones de USD en las principales startups del modelo fundacional. En conjunto, las empresas que fabrican hardware humanoide están valoradas en más de 50 000 millones de USD.
La capa más importante, y la menos desarrollada, es la infraestructura que conecta los modelos entrenados con las implementaciones del mundo real, es decir, las herramientas, los motores de servicio y los sistemas de administración de flotas. Las empresas y los fundadores que desarrollen estas soluciones ocuparán un rol similar al de proveedores de nube como AWS en los modelos de lenguaje: serán la capa crítica sobre la que se construye todo lo demás.

Nikhil Suresh
Nikhil Suresh es inversor en Striker Venture Partners, donde se asocia con fundadores desde antes del primer día para crear empresas que definan categorías en IA, infraestructura y hardware. Nikhil, que fue fundador en serie e investigador de IA en el Scaling Intelligence Lab de Stanford, fue uno de los primeros ingenieros de Mercor que se dedicaba a la búsqueda y el machine learning. Nikhil se centra en ayudar a los equipos de alto potencial a afrontar la fase inicial de formación de productos para crear negocios generacionales y duraderos.

Dhruv Sharma
Dhruv Sharma forma parte del equipo de capital riesgo y startups de AWS, donde se asocia con las principales firmas de capital riesgo y las empresas de su cartera para crear, lanzar y escalar, especialmente en lo que respecta a la infraestructura de IA y las tecnologías de vanguardia. Anteriormente, trabajó durante más de ocho años en capital riesgo y banca de inversión, dirigiendo inversiones y ayudando a las empresas a crecer desde su fase inicial hasta la salida a bolsa.
¿Qué le pareció este contenido?