Comment a été ce contenu ?
- Apprendre
- Modèles de monde et pile d’IA multimodale : réécriture des règles de la robotique
Modèles de monde et pile d’IA multimodale : réécriture des règles de la robotique

Pendant la majeure partie de l’histoire humaine, nous avons découvert le monde et appris à le comprendre par notre corps et notre sens du toucher. Nous avons appris que le feu brûle en nous approchant trop près d’une flamme, et que la glace glisse en tombant. Ce savoir était incarné, acquis par l’expérience directe, et ne pouvait se transmettre qu’au rythme auquel une personne pouvait l’éprouver, l’accumuler et le partager.
Pour transmettre et partager plus largement les connaissances, nous avons dû les formaliser. Les lois du mouvement ont été mises par écrit, la thermodynamique a été codifiée et des systèmes modélisant le comportement du monde ont été construits. Cette approche a jeté les bases de la physique et, pendant trois siècles, ces règles élaborées à la main ont constitué notre seul moyen de donner du sens au monde.
Puis est venue la révolution du machine learning. Au lieu d’encoder manuellement les connaissances, il est devenu possible d’entraîner des systèmes pour qu’ils les apprennent. Les représentations construites à la main ont été remplacées par des représentations apprises, non pas encore pour la physique, mais pour le langage. Le jour où un modèle de transformeur entraîné sur des textes issus d’Internet a pu générer une prose fluide et cohérente, les règles de grammaire que les linguistes avaient passé des décennies à formaliser sont soudain devenues obsolètes. L’écart entre l’ancienne approche, construite à la main, et la nouvelle, fondée sur des représentations apprises, a marqué un basculement structurel majeur. En moins de dix ans, tout l’édifice du traitement du langage naturel (NLP) basé sur des règles s’est effondré.
Un grand bond en avant pour la robotique ?
La robotique et l’IA physique se trouvent aujourd’hui exactement dans la même situation que l’IA du langage en 2005. Chaque simulation repose sur une physique codée à la main. Chaque dynamique de collision, chaque coefficient de frottement et chaque modèle de contact est spécifié par des ingénieurs qui, en pratique, écrivent les règles de grammaire du monde physique.
Un robot entraîné dans l’une de ces simulations peut obtenir de bons résultats dans l’environnement pour lequel il a été créé. Les problèmes apparaissent toutefois si vous le placez dans un environnement inconnu, comme une cuisine, ou si vous lui demandez d’effectuer une nouvelle tâche, comme saisir un objet. Non pas parce que la simulation a été mal conçue, mais en raison de limites structurelles : il n’est pas plus possible de coder manuellement l’intelligence physique générale qu’il ne l’était de coder manuellement GPT-4. La physique codée à la main ne peut pas être mise à l’échelle de l’intelligence physique générale.
Si l’IA du langage a réalisé un tel bond, pourquoi pas la robotique ? Les LLM disposaient d’un avantage considérable : Internet. Avec des milliers de milliards de jetons, déjà numérisés et pratiquement gratuits, les LLM avaient accès au plus vaste corpus de connaissances humaines jamais rassemblé. GPT-4, par exemple, a été entraîné sur environ 13 mille milliards de jetons. La robotique ne dispose d’aucune base de ressources équivalente. Chaque trajectoire robotique, c’est-à-dire chaque instance d’un robot accomplissant une tâche, nécessite du matériel physique, des opérateurs humains, des environnements réels et une organisation minutieuse. Le jeu de données Open X-Embodiment, qui agrège les résultats de 34 laboratoires de robotique dans le monde, en contient environ un million. Cet écart entre les 13 mille milliards de jetons de GPT-4 et un million de trajectoires est immense, et il ne pourra pas être comblé par de simples investissements progressifs.
Une approche entièrement nouvelle de l’acquisition de données est nécessaire. Celle qui émerge aujourd’hui, l’entraînement des robots à partir de vidéos issues d’Internet, pourrait représenter la décision architecturale la plus déterminante de l’histoire de l’IA physique.
Modèles de monde, connaissance du monde et réseaux neuronaux
Un modèle de monde est un réseau neuronal qui apprend l’intuition physique d’une manière proche de l’être humain : par l’observation plutôt que par la formalisation. Comment un enfant apprend-il qu’une balle va rouler et tomber d’une table ? Pas en résolvant la deuxième loi de Newton, ni en exécutant une simulation physique. Il observe, et finit par savoir.
Un modèle de monde fonctionne de la même façon. Montrez-lui des millions d’heures de vidéo, des didacticiels de cuisine, des ateliers, de la circulation, des chantiers, et il commencera à développer une représentation interne du fonctionnement du monde. Ce type de compréhension implicite n’est pas une forme de connaissance de moindre valeur. Il est souvent plus fiable, car plus flexible et plus robuste dans des situations qu’aucun modèle codé à la main n’aurait pu anticiper. Pourquoi est-ce important pour la robotique ? Tout repose sur une distinction entre deux types de connaissances.
La connaissance du monde, comme les exemples montrant comment les objets se comportent sous l’effet de la gravité et comment les matériaux changent, est universelle. Elle n’a rien à voir avec un robot précis. C’est la physique de la réalité elle-même et, heureusement pour le développement de la robotique, Internet regorge de vidéos qui l’illustrent exactement.
La connaissance de l’action, c’est-à-dire la manière dont un robot donné traduit des commandes en mouvements physiques, dépend du matériel et doit être apprise à partir de données propres au robot. Les recherches menées ces deux dernières années ont livré un enseignement clé : une fois que l’on dispose d’une solide connaissance du monde sous-jacente, il ne faut que très peu de connaissance de l’action.
Examinons deux résultats récents qui l’illustrent concrètement. Le premier est V-JEPA 2 de Meta. Ce modèle de monde a été entraîné sur plus d’un million d’heures de vidéos issues d’Internet, puis exposé à seulement 62 heures de vidéos robotiques non étiquetées, sans entraînement propre à une tâche. Il a atteint un taux de réussite sans exemple de 80 % sur des tâches de ramassage et placement dans des laboratoires qu’il n’avait jamais vus auparavant.
Le deuxième est Dreamer 4 de DeepMind. L’agent d’IA a appris à collecter des diamants dans le jeu Minecraft, ce qui exigeait 20 000 décisions séquentielles à partir de pixels bruts, sans aucune interaction avec l’environnement. Ces deux exemples montrent la même dynamique sous-jacente : il est possible de comprendre le fonctionnement du monde physique en exploitant le vaste volume de vidéos disponibles sur Internet. Les données propres aux robots, qui sont rares, n’ont besoin de couvrir que le problème beaucoup plus restreint du mouvement de cette machine en particulier. Le défi de la rareté des données, qui freinait la robotique depuis des années, devient soudain beaucoup plus maîtrisable.
Cinq architectures, une question ouverte
Le terme « modèle de monde » est employé de manière assez large. En pratique, les principales approches divergent profondément sur ce que signifie la représentation physique. Cinq architectures ont émergé, chacune reposant sur une théorie différente de la manière dont les systèmes physiques doivent être encodés dans un système appris. Elles s’accordent sur un point : la simulation codée à la main ne suffit pas. Elles divergent sur presque tout le reste.
Les modèles génératifs vidéo adoptent l’approche la plus directe. Des modèles comme Cosmos de NVIDIA et GWM-1 de Runway fonctionnent tous deux en prédisant les images futures à partir d’une action donnée. Cette approche repose sur l’idée que la vidéo contient suffisamment d’informations sur le monde physique pour entraîner des robots. Son inconvénient est l’efficacité : le modèle mobilise d’importantes ressources pour prédire chaque pixel d’une image, y compris ceux qui n’ont aucun rapport avec la tâche. Genie 3 de DeepMind pousse cette logique le plus loin. Fonctionnant à 24 images par seconde, il s’agit du premier modèle de monde capable de fonctionner en temps réel, comme une simulation interactive en direct.
Les modèles d’espace latent ont produit certains des résultats les plus significatifs. Danijar Hafner et Timothy Lillicrap, chez DeepMind, ont par exemple développé la série Dreamer autour d’une idée simple. Au lieu de prédire l’apparence de la prochaine image vidéo, le modèle construit un résumé interne simplifié de l’état actuel du monde et l’utilise pour simuler la suite. Cette approche est beaucoup plus efficace et a donné des résultats impressionnants :
- Dreamer V2 a été le premier agent à atteindre des performances de niveau humain sur Atari grâce à un modèle de monde.
- Dreamer V3 a surpassé des méthodes spécialisées sur plus de 150 tâches sans optimisation propre à une tâche.
- Dreamer 4 a été entraîné entièrement à partir de données préenregistrées, sans aucune interaction en direct avec l’environnement.
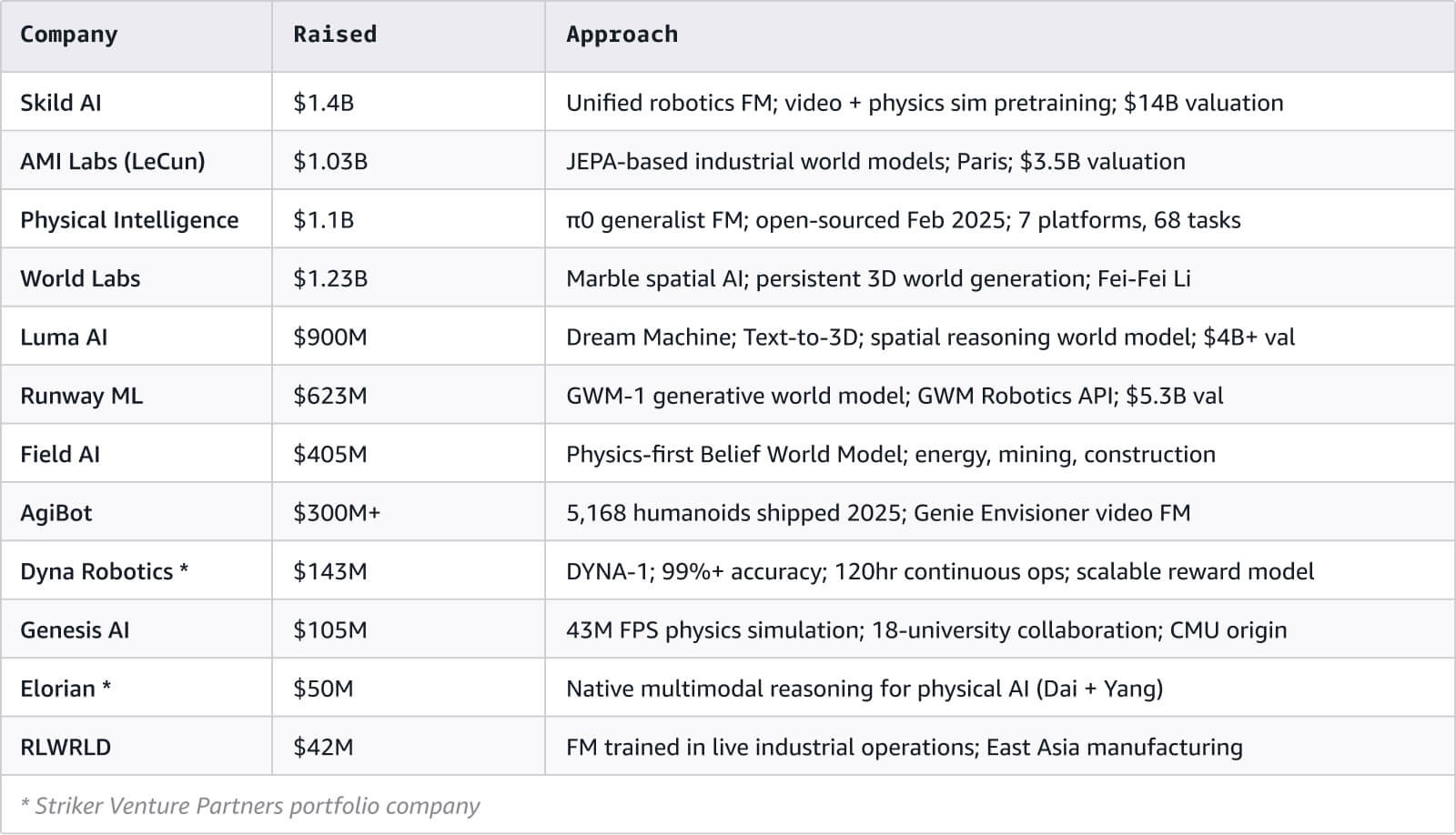
JEPA (Joint Embedding Predictive Architecture, de Yann LeCun) prédit des représentations abstraites plutôt que des pixels. Cette approche repose sur l’idée qu’une compréhension abstraite et conceptuelle du monde, plutôt que des informations visuelles brutes, est plus efficace pour le raisonnement physique. V-JEPA 2 a atteint un taux de réussite sans exemple de 80 % sur des tâches de manipulation en n’utilisant que des vidéos issues d’Internet. Yann LeCun soutient cette approche au point d’avoir fondé AMI Labs à Paris, qui a levé 1,03 milliard de dollars pour une valorisation de 3,5 milliards de dollars avant même d’avoir commercialisé un seul produit.
Le raisonnement multimodal natif repose sur l’idée qu’un système d’IA doit traiter ensemble le texte, les images, la vidéo et l’audio dès sa conception, et non comme des composants séparés assemblés a posteriori. Les quatre autres architectures supposent qu’il est possible de prendre un système conçu pour le texte et d’y ajouter une compréhension physique. Le raisonnement multimodal natif rejette cette idée, en affirmant que greffer une compréhension physique sur un système d’abord conçu pour le texte crée un plafond difficile à dépasser. Elorian, cofondée par Andrew Dai et Yinfei Yang, s’appuie sur cette thèse. Striker Partners a mené le tour de co-amorçage.
Les modèles de monde basés sur la diffusion peuvent fonctionner comme des simulateurs appris à usage général, capables de générer des environnements précis entièrement à partir de dynamiques. Le modèle d’IA agentique DIAMOND a obtenu le score normalisé humain le plus élevé de tous les modèles de monde sur Atari 100k. UniSim a démontré qu’un seul modèle basé sur la diffusion peut simuler la manière dont les humains et les robots interagissent avec le monde physique. Parmi les cinq architectures, les modèles basés sur la diffusion sont les moins éprouvés en robotique réelle.
Il est difficile de savoir si un paradigme dominera ou si les cinq finiront progressivement par fusionner en quelque chose de nouveau. Les données des 18 derniers mois suggèrent une hybridation. La compréhension physique émerge dans les cinq architectures à mesure qu’elles se mettent à l’échelle, et l’écart entre elles se réduit. Lorsque cela se produira, le principal facteur de différenciation ne sera peut-être pas l’architecture, mais la capacité d’une équipe à transformer la recherche en produit le plus rapidement possible.
La mise à l’échelle fonctionne. Pas l’économie.
Le domaine progresse rapidement. Les paramètres des modèles de monde ont été multipliés par environ mille en cinq ans, passant des deux millions de PlaNet aux 14 milliards de Cosmos. Les entraînements rivalisent désormais avec les plus grands efforts consacrés aux modèles de langage : Cosmos a mobilisé 10 000 GPU H100 pendant trois mois. À cette échelle, un phénomène intéressant commence à apparaître.
La compréhension du monde physique commence à émerger comme un effet secondaire inattendu de la mise à l’échelle. Les modèles n’ont pas été programmés pour comprendre les relations de cause à effet dans le monde physique : ils les ont déduites. OpenAI l’a observé dans Sora, par exemple, avec l’apparition d’une cohérence 3D, de la permanence des objets et d’une physique réaliste en raison des propriétés d’échelle du modèle. DeepMind a observé le même phénomène dans Genie 2 avec 11 milliards de paramètres. Le même schéma s’est retrouvé dans chaque architecture, ce qui rend difficile de l’écarter comme une simple coïncidence.
Plusieurs acteurs majeurs ont récemment choisi de publier leurs modèles plutôt que de les garder privés. Cosmos de NVIDIA, V-JEPA 2 de Meta et pi-zero de Physical Intelligence ont tous été publiés en open source en 2025. Dans un domaine concurrentiel, ce signal est révélateur : contribuer à une vaste communauté de recherche devient une meilleure stratégie de progrès que garder ces modèles derrière des portes closes.
Cependant, si les capacités des modèles se sont améliorées, leur coût d’exécution n’a pas suivi. Un modèle de langage textuel coûte environ 15 cents pour 100 heures-utilisateur. Sora coûte 468 USD par heure-utilisateur. Même Odyssey, l’une des options les plus efficaces, nécessite encore un H100 dédié par session à 50 USD/heure. La raison est structurelle : la vidéo doit être générée en continu, en temps réel, image par image. Il n’est pas possible de répartir 50 utilisateurs sur un seul GPU comme avec les modèles de texte, ce qui rapproche l’économie unitaire du calcul cloud haut de gamme plutôt que de la tarification d’API.
Cet écart entre ce que les modèles peuvent faire en recherche et leur coût d’exécution constitue le principal obstacle entre les résultats de laboratoire et le déploiement dans le monde réel. La bonne nouvelle ? Nous avons déjà vu ce type de courbe des coûts. Les coûts d’inférence des LLM ont été divisés par environ mille en trois ans, et Decart revendique déjà une réduction de 400x des coûts vidéo grâce à un moteur conçu sur mesure. Les systèmes d’inférence de production capables de fournir ces performances à grande échelle n’existent pas encore sous forme de produits commerciaux. Les premières équipes à les créer bénéficieront donc d’un solide avantage concurrentiel.
NVIDIA a assemblé la pile d’infrastructure la plus verticalement intégrée dans ce domaine : Cosmos pour l’entraînement des modèles de monde, Isaac Sim pour la simulation physique, GR00T pour les modèles de fondation humanoïdes, Omniverse pour les jumeaux numériques et Jetson Thor pour l’inférence VLA en périphérie. AWS fournit la couche cloud sur laquelle tout cela s’entraîne et se déploie : Amazon SageMaker pour l’entraînement des modèles, AWS Batch pour la simulation à grande échelle et l’orchestration des charges de travail, AWS Inferentia pour l’inférence optimisée, et AWS IoT Greengrass pour la gestion des flottes en périphérie. En production, le schéma est constant : NVIDIA pour la fidélité physique, le cloud pour l’entraînement et l’orchestration des données, et le silicium spécialisé pour le déploiement en temps réel.
Trois lacunes qui détermineront les délais
Le défi de l’infrastructure n’est pas le seul obstacle entre la recherche et le déploiement commercial. Trois lacunes structurelles plus profondes détermineront la rapidité de cette transition.
1. Le manque de données
Le premier est un manque qu’aucun volume de vidéo ne peut combler. La vidéo montre à quoi ressemblent les choses, pas ce que l’on ressent en les touchant. Les tâches impliquant le toucher, comme la manipulation de matériaux, l’insertion de composants ou l’assemblage de pièces, font chuter les performances des modèles d’un niveau impressionnant à un niveau inutilisable. Pourquoi ? Les données d’entraînement ne contiennent aucune information tactile. Une main humaine compte 17 000 récepteurs tactiles. La plupart des mains robotiques déployées, en revanche, n’ont aucun capteur tactile. Bien que les capteurs eux-mêmes existent, il n’existe actuellement aucun jeu de données tactile standardisé à grande échelle. Il ne s’agit pas d’un problème de financement ou de technologie, mais de coordination. Tous les laboratoires bénéficieraient d’un tel jeu de données, mais aucun n’est suffisamment incité à le développer seul. Quiconque résoudra ce problème de coordination, que ce soit par un consortium ouvert ou une approche commerciale des données, accélérera tout le domaine dans une mesure difficile à surestimer.
2. La lacune architecturale
La plupart des entreprises de robotique s’appuient aujourd’hui sur l’apprentissage par imitation : montrer une tâche, puis demander au robot de la reproduire. Cette approche fonctionne pour des tâches simples, mais peine dans des conditions imprévisibles. Lorsque le GRASP Lab de l’UPenn a testé des robots entraînés ainsi dans des conditions véritablement nouvelles, il n’a enregistré qu’un taux de réussite de 16,7 %, très loin de la fiabilité exigée par le monde réel.
Les modèles de monde offrent une approche différente. Un robot peut explorer les modes de défaillance en simulation, parcourir des cas limites sans risque physique et développer ses compétences avant d’être déployé dans le monde réel. Tous les cas documentés de robots fonctionnant en continu pendant au moins 10 heures sans intervention humaine ont utilisé cet apprentissage par renforcement, et non l’apprentissage par imitation. Pour atteindre une fiabilité de niveau industriel, nous devons dépasser la simple imitation et adopter des méthodes d’apprentissage plus robustes.
3. Cohérence temporelle
Les modèles de monde génératifs vidéo peuvent simuler une physique convaincante sur de courtes périodes. Étendus sur des périodes plus longues, ils commencent toutefois à devenir incohérents. Les objets peuvent se retrouver au mauvais endroit, ou un événement censé provoquer une réaction peut ne rien déclencher. Plus la simulation dure, plus les erreurs s’accumulent, jusqu’à ce que le monde simulé ne ressemble plus au monde physique. Genie 3, par exemple, ne reste cohérent que quelques minutes avant que ce type de dérive apparaisse. Ce problème est inhérent à la conception de ces modèles et nécessite donc une solution architecturale. D’autres modèles, comme Marble de World Labs, gèrent mieux la dérive temporelle, mais ils ont tendance à être plus coûteux. Le véritable défi consiste donc à trouver le bon équilibre entre la haute fidélité des simulations et leur coût d’exécution.
Mappage de l’écosystème
Nous avons mappé plus de 120 entités dans l’écosystème des modèles de monde et de l’IA multimodale. La visualisation interactive complète du réseau est incluse avec ce document.
Bon nombre des personnes derrière ces entreprises sont des chercheurs, et non des chefs de produit, qui ont quitté le monde universitaire pour rejoindre de grandes entreprises technologiques. Danijar Hafner et Wilson Yan sont passés de la série Dreamer à Embo, Karol Hausman a quitté l’équipe robotique de DeepMind pour co-fonder Physical Intelligence, et Yann LeCun est passé de Meta AI à AMI Labs.
Le fait que de tels chercheurs acceptent de quitter des postes permanents ou des laboratoires de recherche d’entreprise pour commercialiser la science qu’ils développent signale un changement majeur. La science fondamentale a dépassé le point où le retour attendu du prochain article est supérieur à celui du premier produit.
Quelle vitesse, et qui captera la valeur ?
Chaque transition majeure du machine learning a suivi le même schéma, si constant qu’il ressemble davantage à une loi naturelle qu’à une tendance. Les représentations apprises remplacent les représentations conçues manuellement. Chaque fois que l’IA trouve un moyen d’apprendre automatiquement à partir de données, elle remplace l’ancienne approche dans laquelle les humains encodaient les règles à la main, et cela se produit rapidement. Les modèles de transformeur l’ont fait pour les règles de grammaire codées à la main, et les modèles de monde tentent désormais de faire la même chose pour la physique elle-même, en remplaçant les simulateurs construits manuellement par des modèles appris, entraînés sur des vidéos à l’échelle d’Internet.
La question n’est plus de savoir si cela peut arriver en principe, mais à quelle vitesse cela se produira, quels défis seront résolus en premier et qui captera une valeur durable.
La mise à l’échelle est claire et cohérente d’une architecture à l’autre, et l’économie des données s’améliore. Les coûts d’inférence restent élevés, mais diminuent grâce à la combinaison de conceptions de modèles plus efficaces, d’une meilleure infrastructure de diffusion et du déploiement rapide de matériel d’inférence spécialisé.
Le marché bénéficie aussi d’un important volume de capitaux : plus de 3 milliards de dollars ont été levés par les principales start-ups de modèles de fondation, et les entreprises qui construisent du matériel humanoïde sont valorisées collectivement à plus de 50 milliards de dollars.
La couche la plus importante, et la moins développée, est l’infrastructure qui relie les modèles entraînés aux déploiements dans le monde réel : les outils, les moteurs d’inférence et les systèmes de gestion de flotte. Les entreprises et les fondateurs qui développeront ces solutions occuperont la même position que les fournisseurs cloud comme AWS dans l’univers des modèles de langage : fournir la couche critique dont tout le reste dépend en fin de compte.

Nikhil Suresh
Nikhil Suresh est un investisseur chez Striker Venture Partners, où il travaille en partenariat avec des fondateurs dès leurs débuts pour créer des entreprises qui définissent de nouvelles catégories dans les domaines de l’IA, de l’infrastructure et du matériel. Ancien fondateur en série et chercheur en IA au Scaling Intelligence Lab de Stanford, Nikhil Suresh a déjà été l’un des premiers ingénieurs chez Mercor à travailler sur la recherche et le machine learning. Nikhil s’attache à aider les équipes à fort potentiel à aborder la phase initiale de création de produits afin de créer des entreprises durables et générationnelles.

Dhruv Sharma
Dhruv Sharma fait partie de l’équipe de Capital-risque et start-ups d’AWS, où il travaille en partenariat avec les principales sociétés de capital-risque et les entreprises de leur portefeuille pour créer, lancer et développer, en particulier dans les domaines des infrastructures d’IA et des technologies de pointe. Auparavant, il a passé plus de huit ans dans le domaine du capital-risque et de la banque d’investissement, où il a dirigé des investissements et aidé des entreprises à se mettre à l’échelle, du stade de démarrage à l’introduction en bourse.
Comment a été ce contenu ?