Come ti è sembrato il contenuto?
- Scopri
- I modelli globali e lo stack di IA multimodale: riscrivere le regole della robotica
I modelli globali e lo stack di IA multimodale: riscrivere le regole della robotica

Per gran parte della storia umana, abbiamo imparato a conoscere e a comprendere il mondo attraverso il nostro corpo e il senso del tatto. Abbiamo imparato che il fuoco brucia avvicinandoci troppo a una fiamma e che il ghiaccio è scivoloso cadendo. Questa conoscenza era incarnata, acquisita attraverso l’esperienza diretta, e poteva diffondersi solo nella misura in cui una persona era in grado di sperimentarla, accumularla e trasmetterla.
Per trasmettere e condividere le conoscenze in modo più ampio, abbiamo dovuto formalizzarle. Le leggi del moto sono state messe per iscritto, la termodinamica è stata codificata e sono stati costruiti sistemi che modellavano il comportamento del mondo reale. Questo approccio ha gettato le basi della fisica e, per tre secoli, queste regole elaborate con cura sono state l’unico mezzo a nostra disposizione per dare un senso al mondo reale.
Poi è arrivata la rivoluzione del machine learning e, invece di codificare manualmente la conoscenza, i sistemi potevano essere addestrati ad apprenderla. Le rappresentazioni create a mano sono state sostituite da quelle apprese, non ancora per la fisica, ma per il linguaggio. Nel momento in cui un modello di trasformatore addestrato su testi provenienti da Internet è stato in grado di generare una prosa fluida e coerente, le regole grammaticali che i linguisti avevano impiegato decenni a scrivere sono diventate improvvisamente obsolete. Il divario tra il vecchio approccio, basato sulla creazione manuale, e il nuovo, quello delle rappresentazioni apprese, ha segnato un importante cambiamento strutturale. In meno di un decennio, l’intera struttura dell’elaborazione del linguaggio naturale basata su regole è crollata.
Un grande passo avanti per la robotica?
Oggi la robotica e l’IA applicata alla fisica si trovano esattamente nella stessa situazione in cui si trovava l’IA applicata al linguaggio nel 2005. Ogni simulazione si basa su una fisica codificata manualmente. Ogni dinamica di collisione, ogni coefficiente di attrito e ogni modello di contatto sono specificati da ingegneri che, di fatto, scrivono le regole grammaticali del mondo fisico.
Un robot addestrato in una di queste simulazioni può funzionare bene nell’ambiente per cui è stato creato. Tuttavia, i problemi sorgono se lo si porta in un ambiente non familiare, come una cucina, o se gli si chiede di svolgere una nuova attività, come afferrare un oggetto. Non perché la simulazione sia stata realizzata male, ma a causa di difetti strutturali: non si può programmare manualmente un’intelligenza fisica generale, così come non si potrebbe programmare manualmente un GPT-4. La fisica programmata manualmente non è scalabile fino a raggiungere un’intelligenza fisica generale.
Se l’IA applicata al linguaggio ha fatto un balzo in avanti così spettacolare, perché non dovrebbe riuscirci anche la robotica? I modelli linguistici avevano un vantaggio significativo: Internet. Con trilioni di token, già digitalizzati ed essenzialmente gratuiti, i modelli linguistici di grandi dimensioni (LLM) avevano accesso al più grande corpus di conoscenza umana mai assemblato. GPT-4, ad esempio, è stato addestrato su circa 13 trilioni di token. La robotica non ha una base di risorse equivalente. Ogni traiettoria di un robot (un’istanza di un robot che completa un’attività) richiede hardware fisico, operatori umani, ambienti reali e un’accurata cura. Il set di dati Open X-Embodiment, l’output combinato di trentaquattro laboratori di robotica in tutto il mondo, ne contiene circa un milione. Quel divario, tra i tredici milioni di token di GPT-4 e il milione di traiettorie, è enorme e non può essere colmato con investimenti incrementali.
È necessario un approccio completamente nuovo all’acquisizione dei dati. E quello che sta emergendo, ovvero l’addestramento dei robot tramite video su Internet, potrebbe rappresentare la decisione architetturale più importante nella storia dell’IA applicata alla fisica.
Modelli globali, conoscenza globale e reti neurali
Un modello globale è una rete neurale che apprende l’intuizione fisica in modo simile a come fanno gli esseri umani, attraverso l’osservazione piuttosto che la formalizzazione. Come fa un bambino a imparare che una palla rotolerà via da un tavolo? Non risolvendo la seconda legge di Newton, né eseguendo una simulazione fisica. Osserva e, alla fine, lo sa.
Un modello globale funziona allo stesso modo. Mostrategli milioni di ore di video, tutorial di cucina, ambienti di fabbrica, traffico, cantieri edili, e inizierà a sviluppare un’immagine interna di come si comporta il mondo intero. Questo tipo di comprensione implicita non è una forma di conoscenza meno preziosa. Spesso è più affidabile, perché è più flessibile e resiste in situazioni che nessun modello programmato manualmente avrebbe potuto prevedere. Perché questo è importante per la robotica? Tutto si riduce a una distinzione tra due tipi di conoscenza.
La conoscenza globale, come il comportamento degli oggetti sotto l’effetto della gravità e le trasformazioni dei materiali, è fondamentale. Non ha nulla a che vedere con il robot specifico. Si tratta della fisica della realtà stessa e, fortunatamente per lo sviluppo della robotica, Internet è pieno di video che dimostrano proprio questo concetto.
La conoscenza dell’azione, ossia il modo in cui uno specifico robot traduce i comandi in movimento fisico, è specifica dell’hardware e deve essere appresa da dati specifici del robot stesso. La ricerca condotta negli ultimi due anni ha fornito un’intuizione fondamentale: una volta acquisita una solida conoscenza globale, sarà necessaria una conoscenza dell’azione molto limitata.
Analizziamo due risultati recenti che illustrano questo concetto nella pratica. Il primo è il V-JEPA 2 di Meta. Il modello globale è stato addestrato su oltre un milione di ore di video provenienti da Internet, per poi essere sottoposto a sole 62 ore di video di robot non etichettati e senza alcun addestramento specifico per l’attività. Ha raggiunto l’80% di successo zero-shot in attività di prelievo e posizionamento in laboratori che non aveva mai visto prima.
Il secondo è Dreamer 4 di DeepMind. L’agente IA ha imparato a raccogliere diamanti nel gioco Minecraft, un’operazione che richiedeva 20.000 decisioni sequenziali a partire da pixel grezzi, senza alcuna interazione con l’ambiente. Entrambi gli esempi indicano la stessa dinamica di fondo: è possibile comprendere come funziona il mondo fisico utilizzando la vasta quantità di video già disponibili su Internet. I dati specifici del robot, che sono scarsi, devono solo riguardare il problema, ben più circoscritto, di come si muove quella particolare macchina. La sfida della scarsità di dati, che ha frenato la robotica per anni, diventa improvvisamente molto più gestibile.
Cinque architetture, una domanda aperta
Il termine “modello globale” viene usato in modo approssimativo. Nella pratica, gli approcci principali sono profondamente in disaccordo sul significato della rappresentazione fisica. Sono emerse cinque architetture, ciascuna basata su una diversa teoria di come i sistemi fisici devono essere codificati in un sistema di apprendimento, che concordano solo sul fatto che la simulazione codificata manualmente sia insufficiente. Sono invece in disaccordo su quasi tutto il resto.
I modelli video-generativi adottano l’approccio più diretto. Modelli come Cosmos di NVIDIA e GWM-1 di Runway funzionano prevedendo i fotogrammi futuri, a condizione che si sia verificata una specifica azione. Questo si basa sull’idea che i video catturino informazioni sufficienti sul mondo fisico per poter addestrare i robot. Lo svantaggio, in questo caso, è l’efficienza, poiché il modello utilizza risorse considerevoli per prevedere ogni singolo pixel di un fotogramma, inclusi quelli irrilevanti per l’attività. Genie 3 di DeepMind spinge questo concetto all’estremo. Con una velocità di 24 fotogrammi al secondo, è il primo modello globale che funziona in tempo reale, fungendo da simulazione interattiva e giocabile.
I modelli spaziali latenti hanno prodotto alcuni dei risultati più significativi. Danijar Hafner e Timothy Lillicrap di DeepMind, ad esempio, hanno sviluppato la serie Dreamer partendo da un’idea semplice. Invece di prevedere l’aspetto del fotogramma video successivo, il modello crea un riepilogo interno semplificato dello stato attuale del mondo reale e lo utilizza per simulare ciò che accadrà dopo. Questo metodo è molto più efficiente e ha dato risultati notevoli:
- Dreamer V2 è stato il primo agente a raggiungere prestazioni di livello umano su Atari attraverso un modello globale.
- Dreamer V3 ha superato i metodi specializzati in oltre 150 attività senza necessità di ottimizzazione specifica per ciascuna attività.
- Dreamer 4 è stato addestrato interamente con dati preregistrati, senza alcuna interazione con l’ambiente reale.
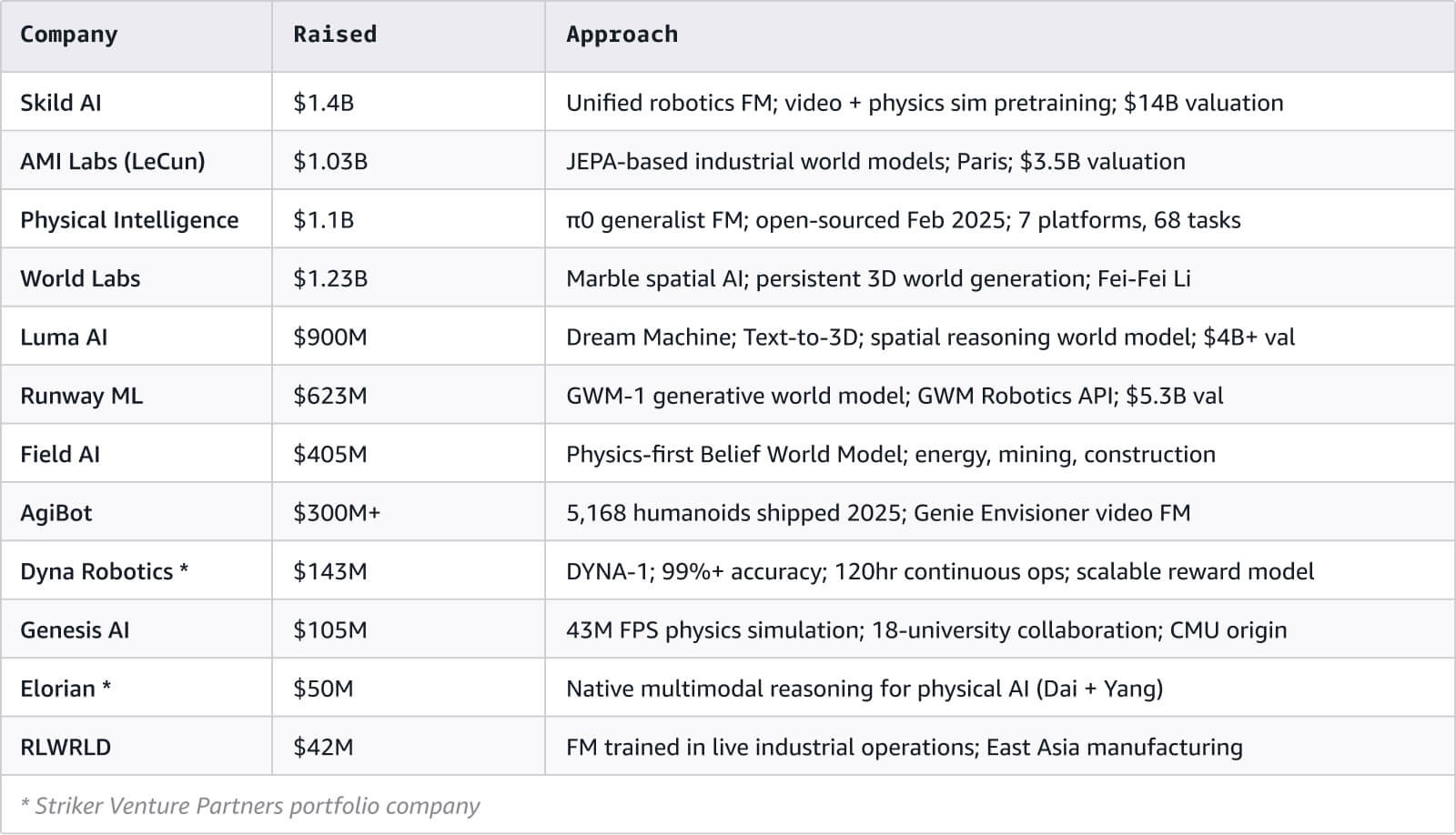
JEPA (la Joint Embedding Predictive Architecture, ovvero architettura predittiva di embedding congiunto, di Yann LeCun) prevede rappresentazioni astratte anziché pixel. Si basa sull’idea che una comprensione astratta e concettuale del mondo sia più efficace delle informazioni visive grezze per il ragionamento fisico. V-JEPA 2 ha raggiunto l’80% di successo zero-shot in attività di manipolazione utilizzando solo video da Internet. LeCun sostiene questo approccio al punto da aver fondato AMI Labs a Parigi, che ha raccolto 1,03 miliardi di dollari con una valutazione di 3,5 miliardi di dollari prima ancora di aver commercializzato un singolo prodotto.
Il ragionamento multimodale nativo è l’idea che un sistema di IA debba elaborare testo, immagini, video e audio insieme fin dalle fondamenta, non come componenti separati assemblati. Le altre quattro architetture presuppongono che si possa prendere un sistema costruito per il testo e aggiungervi la comprensione fisica. Il ragionamento multimodale nativo rifiuta questa tesi, sostenendo che l’applicazione a posteriori della comprensione fisica a sistemi incentrati sul testo pone un limite invalicabile alle sue potenzialità. Elorian, cofondata da Andrew Dai e Yinfei Yang, si basa proprio su questa tesi. Striker Partners ha guidato il round di finanziamento iniziale.
I modelli globali basati sulla diffusione possono funzionare come simulatori di apprendimento generici, generando ambienti accurati interamente a partire dalle dinamiche. Il modello di IA agentica DIAMOND ha ottenuto il punteggio più alto, normalizzato rispetto alle prestazioni umane, tra tutti i modelli globali su Atari 100k. UniSim ha dimostrato che un singolo modello basato sulla diffusione può simulare il modo in cui sia gli esseri umani che i robot interagiscono con il mondo fisico. Delle cinque architetture, i modelli basati sulla diffusione sono i meno testati nella robotica del mondo reale.
Non è chiaro se prevarrà un paradigma o se le cinque architetture si fonderanno gradualmente in qualcosa di nuovo. Le evidenze degli ultimi 18 mesi suggeriscono un’ibridazione. La comprensione dei principi fisici sta emergendo durante il processo di scalabilità in tutte e cinque le architetture, e il divario tra ciascuna si sta riducendo. Quando ciò accadrà, il fattore di differenziazione principale potrebbe non essere di natura architetturale, ma dipendere da quale team sarà in grado di trasformare la ricerca in produzione più rapidamente.
La scala funziona. Gli aspetti economici no.
Il settore sta progredendo a ritmo serrato. I parametri dei modelli globali si sono moltiplicati di circa mille volte in cinque anni, passando dai due milioni di PlaNet ai 14 miliardi di Cosmos. Le sessioni di addestramento ora competono con i più grandi progetti di modelli linguistici: Cosmos ha consumato 10.000 GPU H100 per tre mesi. A questa scala, comincia ad accadere qualcosa di interessante.
La comprensione del mondo fisico sta emergendo come effetto collaterale non intenzionale della scala. I modelli non sono stati programmati per comprendere il rapporto causa-effetto nel mondo fisico, bensì lo hanno elaborato. OpenAI lo ha osservato in Sora, ad esempio, dove la coerenza 3D, la permanenza degli oggetti e la fisica realistica sono emerse come risultato delle proprietà di scala nel modello. DeepMind ha osservato lo stesso fenomeno in Genie 2 con 11 miliardi di parametri. Lo stesso schema si è ripetuto per ogni architettura, rendendo difficile liquidarlo come una semplice coincidenza.
Recentemente, diversi attori di spicco hanno scelto di rendere pubblici i propri modelli anziché mantenerli privati. Cosmos di NVIDIA, V-JEPA 2 di Meta e pi-zero di Physical Intelligence sono stati tutti resi open source nel 2025. In un settore competitivo, questo è un segnale significativo, che suggerisce come contribuire a un’ampia comunità di ricerca stia diventando una strategia più efficace per il progresso rispetto al mantenere i propri progetti riservati.
Tuttavia, sebbene la capacità dei modelli sia migliorata, il costo della loro gestione non è diminuito. Un modello di linguaggio testuale costa circa quindici centesimi per cento ore utente. Sora costa 468 dollari per ora utente. Persino Odyssey, tra le opzioni più efficienti, richiede ancora un processore H100 dedicato per sessione, al costo di 50 dollari l’ora. La ragione è strutturale: il video deve essere generato continuamente, in tempo reale, fotogramma per fotogramma. Non è possibile distribuire 50 utenti su una singola GPU come fanno i modelli di testo, il che significa che i costi unitari sono più simili a quelli del cloud computing premium che a quelli delle API.
Questo divario tra ciò che i modelli possono fare nella ricerca e il costo per la loro esecuzione è il principale ostacolo tra i risultati di laboratorio e la distribuzione nel mondo reale. La buona notizia? Abbiamo già visto questo tipo di curva dei costi. I costi di inferenza degli LLM sono diminuiti di circa mille volte in tre anni e Decart afferma già di aver ottenuto una riduzione dei costi di 400 volte per i video grazie a un motore personalizzato. I sistemi di inferenza di livello produttivo che consentiranno di raggiungere questi risultati su larga scala non sono ancora disponibili sul mercato. Pertanto, i team che li svilupperanno per primi otterranno un forte vantaggio competitivo.
NVIDIA ha creato l’infrastruttura più integrata verticalmente in questo settore: Cosmos per l’addestramento dei modelli globali, Isaac Sim per la simulazione fisica, GR00T per i modelli di fondazione umanoidi, Omniverse per i gemelli digitali e Jetson Thor per l’inferenza VLA edge. AWS fornisce il livello cloud su cui tutti questi modelli vengono addestrati e distribuiti: Amazon SageMaker per l’addestramento dei modelli, AWS Batch per la simulazione su larga scala e l’orchestrazione del carico di lavoro, AWS Inferentia per l’inferenza ottimizzata e AWS IoT Greengrass per la gestione del parco edge. In produzione, lo schema è coerente: NVIDIA per la fedeltà fisica, cloud per l’addestramento e l’orchestrazione dei dati, processore dedicato per la distribuzione in tempo reale.
Le tre lacune che determinano le tempistiche
La sfida infrastrutturale non è l’unico ostacolo tra la ricerca e la sua distribuzione commerciale. Esistono tre lacune strutturali più profonde che determineranno la velocità con cui avverrà questa transizione.
1. Il divario nei dati
Il primo problema è una lacuna che nessun video può colmare. I video catturano l’aspetto delle cose, non la loro consistenza. Le attività che implicano il tatto, come la manipolazione di materiali, l’inserimento di componenti o l’assemblaggio di parti, comportano un calo delle prestazioni del modello, che passano da eccellenti a inutilizzabili. Perché? Nei dati di addestramento mancano informazioni tattili. Si consideri che una mano umana contiene 17.000 recettori tattili. La maggior parte delle mani robotiche attualmente in uso, d’altro canto, non possiede alcun sensore tattile. Nonostante i sensori siano disponibili, al momento non esiste un set di dati tattili standardizzato e ampiamente diffuso. Non si tratta di una mancanza di finanziamenti o di tecnologia, bensì di una mancanza di coordinamento. Ogni laboratorio trarrebbe vantaggio da un simile set di dati, ma nessuno ha sufficienti incentivi per crearlo da solo. Chiunque risolva questo problema di coordinamento, sia attraverso un consorzio aperto che tramite un’iniziativa commerciale basata sui dati, accelererà l’intero settore in misura difficilmente quantificabile.
2. Il divario architettonico
Oggi la maggior parte delle aziende di robotica si affida all’apprendimento per imitazione: si dimostra un’attività e il robot la replica. Questo metodo funziona per compiti semplici, ma presenta delle difficoltà in condizioni imprevedibili. Quando il GRASP Lab dell’Università della Pennsylvania (UPenn) ha testato robot addestrati in questo modo in condizioni realmente nuove, ha registrato un tasso di successo di appena il 16,7%, ben lontano dall’affidabilità richiesta dalle condizioni reali.
I modelli globali offrono un approccio diverso. Un robot può esplorare le modalità di guasto in simulazione, iterare attraverso casi limite senza rischi fisici e acquisire competenze prima di essere impiegato nel mondo reale. Ogni caso documentato di un robot che opera ininterrottamente per 10 ore o più senza intervento umano ha utilizzato questo tipo di apprendimento per rinforzo, non per imitazione. Per raggiungere un’affidabilità di livello industriale, dobbiamo andare oltre la semplice imitazione e adottare metodi di apprendimento più robusti.
3. Coerenza temporale
I modelli globali video-generativi possono simulare una fisica convincente per brevi periodi. Se estesi a periodi più lunghi, iniziano a diventare incoerenti. Gli oggetti potrebbero finire nel posto sbagliato o qualcosa che dovrebbe provocare una reazione potrebbe non provocarla. Più a lungo dura la simulazione, più gli errori si accumulano, fino a quando il mondo simulato non assomiglia più a quello fisico. Genie 3, ad esempio, è coerente solo per pochi minuti prima che si manifesti questo tipo di deriva. È un problema intrinseco alla progettazione di questi modelli, quindi richiede una soluzione architetturale. Altri modelli, come Marble di World Labs, gestiscono meglio la deriva temporale, ma tendono ad essere più costosi. La vera sfida, quindi, consiste nel trovare il giusto equilibrio tra simulazioni ad alta fedeltà e il costo della loro esecuzione.
Mappatura dell’ecosistema
Abbiamo mappato oltre 120 entità nei modelli globali e nell’ecosistema multimodale dell’IA. La visualizzazione interattiva completa della rete è inclusa in questo documento.
Molte delle persone che stanno dietro a queste aziende sono ricercatori, non product manager, e hanno lasciato il mondo accademico per unirsi a grandi marchi tecnologici. Hafner e Yan sono passati dalla serie Dreamer a Embo, Hausman ha lasciato il team di robotica di DeepMind per cofondare Physical Intelligence, LeCun è passato da Meta AI ad AMI Labs.
La disponibilità di questi ricercatori ad abbandonare i propri ruoli a tempo indeterminato e i laboratori di ricerca aziendali per commercializzare la scienza che stanno sviluppando segnala un cambiamento epocale. La scienza di base è maturata al punto che il ritorno sull’investimento derivante dalla prossima pubblicazione supera quello derivante dal primo prodotto.
Chi riesce a generare valore e con quale rapidità?
Ogni grande transizione nel machine learning ha seguito lo stesso schema, così coerente da assomigliare più a una legge naturale che a una tendenza. Le rappresentazioni apprese sostituiscono quelle create manualmente. Ogni volta che l’IA trova un modo per apprendere qualcosa automaticamente dai dati, sostituisce il vecchio approccio degli esseri umani che codificano manualmente le regole, e questo processo sta avvenendo rapidamente. I trasformatori lo hanno fatto per le regole grammaticali codificate manualmente e i modelli globali stanno ora cercando di fare lo stesso per la fisica stessa, sostituendo i simulatori costruiti manualmente con modelli appresi addestrati su video su scala Internet.
La questione ora non è se ciò accadrà in linea di principio, ma con quale rapidità, quali problematiche verranno risolte per prime e chi ne trarrà un valore duraturo.
La scalabilità è chiara e coerente tra le diverse architetture e l’economia dei dati sta migliorando. I costi di inferenza sono ancora elevati, ma in calo, grazie a una combinazione di modelli più efficienti, infrastrutture di servizio migliori e alla rapida distribuzione di hardware di inferenza specializzato.
Inoltre, il mercato è sostenuto da un’ingente quantità di capitali: le principali startup che adottano i modelli di fondazione hanno raccolto oltre 3 miliardi di dollari, e le aziende che sviluppano hardware per robot umanoidi hanno, nel complesso, una valutazione di oltre 50 miliardi di dollari.
Lo strato più importante, e quello meno sviluppato, è l’infrastruttura che collega i modelli addestrati alle distribuzioni nel mondo reale: gli strumenti, i motori di erogazione e i sistemi di gestione del parco. Le aziende e i fondatori che creano queste soluzioni occuperanno la stessa posizione che i provider di servizi cloud come AWS occupano nel mondo dei modelli linguistici: fornire lo strato critico da cui, in definitiva, dipende tutto il resto.

Nikhil Suresh
Nikhil Suresh è un investitore di Striker Venture Partners, dove collabora con i fondatori sin dal primo giorno per creare aziende che definiscono la categoria in materia di intelligenza artificiale, infrastruttura e hardware. Ex fondatore seriale e ricercatore di intelligenza artificiale presso lo Scaling Intelligence Lab di Stanford, Nikhil è stato in precedenza uno dei primi ingegneri di Mercor lavorando su Search e ML. Nikhil si concentra sull'aiutare i team ad alto potenziale ad affrontare la fase iniziale della formazione del prodotto per creare attività durature e generazionali.

Dhruv Sharma
Dhruv Sharma fa parte del team Venture Capital & Startups di AWS, dove collabora con le principali società di venture capital e le relative società in portafoglio per creare, lanciare e scalare, in particolare nell'ambito dell'infrastruttura di intelligenza artificiale e delle tecnologie di frontiera. In precedenza, ha lavorato per oltre otto anni nel venture capital e nell'investment banking, guidando gli investimenti e aiutando a far crescere le aziende dalla fase iniziale all'IPO.
Come ti è sembrato il contenuto?