このコンテンツはいかがでしたか?
- 学ぶ
- ワールドモデルとマルチモーダル AI スタック: ロボティクスのルールを書き換える
ワールドモデルとマルチモーダル AI スタック: ロボティクスのルールを書き換える

人類の歴史のほとんどにおいて、私たちは身体と触覚を通して世界について学び、理解してきました。炎に近づきすぎると火傷すること、氷は転ぶと滑りやすいことがわかりました。こうした知識は身体に宿り、直接の経験を通して得られ、一人の人間がそれを経験し、蓄積し、伝える速度でしか広まることができませんでした。
知識をより広く伝え、共有するためには、それを体系化する必要がありました。運動の法則が書き記され、熱力学が体系化され、世界の動きをモデル化するシステムが構築されました。このアプローチは物理学の基礎を築き、3世紀の間、これらの手作業で作りあげられた規則こそが、私たちが世界を理解するための唯一の手段だったのです。
その後、機械学習革命が起こり、知識を手動で符号化する代わりに、システムに知識を学習させることができるようになりました。手作業で構築された表現は、物理学 (今のところ) のためではなく、言語のための学習された表現に置き換えられました。インターネットからのテキストでトレーニングされたトランスフォーマーモデルが流暢で首尾一貫した散文を生成できるようになった瞬間、言語学者が何十年もかけて書き留めてきた文法規則は突然時代遅れになりました。手作業の古いアプローチと、学習された表現という新しいアプローチとのギャップは、構造的に大きな変化をもたらしました。10 年も経たないうちに、ルールベースの自然言語処理という体系全体が崩壊してしまいました。
ロボティクスにおける大きな飛躍とは?
今日のロボットティクスと物理 AI は、2005 年の言語 AI とまったく同じ状況にあります。すべてのシミュレーションは、手実装の物理挙動に基づいて構築されています。あらゆる衝突力学、あらゆる摩擦係数、あらゆる接触モデルは、事実上、物理世界の文法規則を書いているエンジニアによって指定されています。
これらのシミュレーションのいずれかで訓練されたロボットは、そのロボットが作られた環境でうまく機能することができます。しかし、キッチンなどのなじみのない環境に持ち込んだり、物をつかむなどの新しいタスクを実行させたりすると、問題が発生します。シミュレーションの構築が不十分だったからではなく、構造上の障害が原因です。GPT-4 を手書きルールで作れないのと同じように、手実装の物理ルールでは、汎用的な物理知能に到達することはできません。手実装の物理では、汎用的な物理知能には対応できないのです。
言語 AI がこれほど劇的な飛躍を遂げたのに、なぜロボティクスはそうならないのでしょうか? LLM にはインターネットという大きな利点がありました。既にデジタル化され、実質的に無料の何兆ものトークンを利用できたため、LLMは、これまで人類が集積した最大の知識コーパスにアクセスできました。例えば、GPT-4は約 13 兆個のトークンでトレーニングされました。ロボティクスにはこれに匹敵するリソースベースはありません。ロボットの軌跡 (タスクを完了するロボットの個々の事例) には、物理的なハードウェア、人間のオペレーター、実環境、そして入念なキュレーションが必要です。世界中の 34 のロボティクスの成果を統合した Open X-Embodiment のデータセットには、約 100万件の軌跡が含まれています。GPT-4 の 1,300 万トークンと 100 万の軌跡との差は非常に大きく、段階的な投資では埋めることはできません。
データ収集にはまったく新しいアプローチが必要です。そして、今まさに現れつつあるインターネット動画を使ってロボットを訓練するというアプローチは、物理 AI の歴史において最も重大なアーキテクチャ上の決断になるかもしれません。
ワールドモデル、世界知識、そしてニューラルネットワーク
ワールドモデルは、人間と同じように、形式化ではなく観察を通じて物理的な直感を学習するニューラルネットワークです。子供はどうやって、ボールがテーブルから転がり落ちるということを知るのでしょうか? ニュートンの第二法則を解いたり、物理シミュレーションを行ったりするわけではありません。ただ見て、やがてわかるようになるのです。
ワールドモデルも同じように機能します。何百万時間もの動画 (調理チュートリアル、工場の現場、交通、建設現場など) を見せれば、世界がどのように振る舞うかについて内部的なイメージが浮かび上がるでしょう。このような暗黙の理解は、価値の低い知識形態ではありません。むしろ、多くの場合、こちらの方が信頼性が高くなります。より柔軟で、手作りのモデルでは予想できなかったような状況でも破綻しないからです。では、なぜこれがロボテイクスにとって重要なのでしょうか? 結局のところ、それは、2 種類の知識の違いに行き着きます。
重力下での物体の挙動や物質の変化の例など、世界知識は普遍的です。これは、特定のロボットには関係ありません。それは現実そのものの物理法則であり、ロボティクスの発展にとって幸いなことに、インターネットはまさにこれを実証する動画であふれています。
アクション知識とは、特定のロボットがどのようにコマンドを物理的な動きに変換するかと言う知識であり、ハードウェア固有のものです。そのため、ロボット固有のデータから学習する必要があります。過去 2 年間にわたって集められた研究から、重要な知見が得られました。それは、いったんしっかりした世界知識を身につければ、アクション知識はほとんど必要ないということです。
これを実際に説明する最近の 2 つの成果を見てみましょう。まずは、Meta の V-JEPA 2 です。このワールドモデルは 100 万時間を越えるインターネット動画でトレーニングされ、その後はタスク固有のトレーニングを一切せず、ラベル付けされていないロボット動画を わずか 62 時間与えられました。これまでに見たことのない複数のラボにおけるピック&プレースタスクの作業で、80% のゼロショット成功率を達成しました。
次に、DeepMind の Dreamer 4 です。AI エージェントは、ゲーム「Minecraft」でダイヤモンドを集める方法を学習しました。このゲームでは、生のピクセル入力から 20,000 回の連続した意思決定が必要で、環境との相互作用は一切ありませんでした。どちらの例も、同じ根本的なダイナミクスを示しています。つまり、物理世界がどのように機能するかを理解するには、既に存在する膨大な量のインターネット動画を使用すれば達成できるということです。乏しいロボット固有のデータが必要とするのは、その特定の機械がどのように動くかというはるかに小さな問題をカバーすることだけです。長年ロボティクスを妨げてきたデータ不足の課題が、ここにきて一気に扱いやすいものになりました。
5 つのアーキテクチャ、1 つの未解決問題
「ワールドモデル」という用語は大まかに用いられています。実際には、主要なアプローチ間では物理的表現が何を意味するのかについて大きく意見が分かれています。これまでに、5 つのアーキテクチャが登場しており、それぞれが物理システムを学習済みシステムにどのように符号化すべきかという異なる理論に基づいています。彼らは、手作業でコーディングされたシミュレーションでは不十分だという点で意見が一致しています。彼らは他のほとんどすべてについて意見が分かれています。
動画生成モデルは、最もストレートな方法を取ります。NVIDIA の Cosmos や Runway の GWM-1 のようなモデルはどちらも、特定のアクションが行われたことを前提として、将来のフレームを予測することで動作します。これは、動画にはロボットを訓練するのに十分な物理世界の情報が含まれているという発想に基づいています。この方法の欠点は効率性です。というのも、このモデルは、タスクに関係のないものまで含めて、フレーム内の全ピクセルを予測するために大量のリソースを使用するからです。DeepMind の Genie 3 は、この方向性を極限まで押し広げています。毎秒 24 フレームで動作するこのモデルは、リアルタイムで動作し、ライブでプレイ可能なシミュレーションとして機能する、世界初のワールドモデルです。
潜在空間モデルは、最も重要な結果をいくつか生み出してきました。例えば、DeepMind の Danijar Hafner と Timothy Lillicrap は、シンプルな発想を軸に Dreamer シリーズを開発しました。このモデルは、次の動画フレームがどのように見えるかを予測する代わりに、世界の現在の状態を簡略化した内部表現 (要約) を構築し、それを使って次に何が起こるかをシミュレートします。この方法ははるかに効率的で、いくつもの印象的な成果を上げています。
- Dreamer V2は、ワールドモデルを通じて Atari で人間レベルのパフォーマンスを達成した最初のエージェントでした。
- Dreamer V3 は、タスク固有の調整を一切行わずに、150 を超えるタスクで接門的な手法を凌駕する性能を発揮しました。
- Dreamer 4 は、すべて事前に録画されたデータからトレーニングされ、ライブ環境でのやり取りは一切行っていません。
JEPA (Yann LeCun 氏の Joint Embedding Predictive Architecture) は、ピクセルではなく抽象的な表現を予測します。これは、生の視覚情報よりも、世界の抽象的で概念的な理解の方が物理的な推論には有効であるという考えに基づいています。V-JEPA 2 は、インターネット動画のみを使用したマニピュレーションタスクで、ゼロショット成功率が 80% に達しました。LeCun 氏はこのアプローチを強く支持し、パリに AMI Labs を設立しました。AMI ラボは、製品をまだ 1 つも世に出していない段階で、35 億 米ドルの評価額で 10 億 3,000 万米ドルを調達しています。
ネイティブマルチモーダル推論とは、AI システムがテキスト、画像、動画、オーディオを後から寄せ集めた別々のコンポーネントとして扱うのではなく、最初から統合された形で処理するべきたという考えです。他の 4 つのアーキテクチャでは、テキスト用に構築されたシステムに物理的理解を後付けできると想定しています。しかし、ネイティブマルチモーダル推論はこれを否定し、物理的理解をテキスト優先のシステムに組み込むと、達成できることの上限が厳しくなると主張しています。Andrew Dai 氏と Yinfei Yang 氏が共同設立した Elorian は、この仮説に基づいて開発を進めています。共同シードラウンドを Striker Partners が主導しています。
ディフュージョンベースのワールドモデルは、汎用的な学習シミュレーターとして機能し、ダイナミクスだけから正確な環境を生成する場合があります。エージェンティック AI モデルの DIAMOND は、Atari 100k において、あらゆるワールドモデルの中で最高の人間正規化によるスコアを達成しました。UniSim は、単一のディフュージョンベースのモデルで、人間とロボットの両方が物理世界とどのように相互作用するかをシミュレートできることを示しました。5 つのアーキテクチャのうち、ディフュージョンベースのモデルは実世界のロボティクスでの検証が最も少ないモデルです。
どれか 1 つのパラダイムが主流となるか、それとも 5 つのパラダイムが徐々に融合して新しい形へと変わるのかはまだわかっていません。過去 18 か月間の動向を見ると、ハイブリット化が進んでいることが示唆されています。5 つのアーキテクチャはいずれもスケールするにつれて、物理理解が現れ始めてきており、アーキテクチャ間の差は縮まりつつあります。そうなったとき、最大の差別化要因はアーキテクチャそのものではなく、どのチームが研究成果を最速で本番環境に落とし込めるかという点になるかもしれません。
スケールには対応しています。経済性はうまくいっているわけではありません。
この分野は急速に進歩しています。ワールドモデルのパラメータは、PlaNet の 200 万から Cosmos の 140 億へと、5 年間でおよそ 1000 倍に膨れ上がりました。 現在、トレーニングの実行は最大級の大規模言語モデルの取り組みに匹敵します。Cosmos は 3 か月間で 10,000 台の H100 GPU を消費しました。この規模になると、何か興味深いことが起こり始めます。
物理世界の理解は、スケール拡大に伴う予期せぬ副産物として現れ始めています。モデルは、物理世界における因果関係を理解するようにはプログラムされていたわけではなく、むしろ自らそれを獲得したのです。OpenAI は、例えば Sora でこれを確認しています。モデル内のスケール特性の結果として、3D の一貫性、オブジェクトの永続性、現実的な物理挙動が自然に現れたからです。 DeepMind も 110 億個のパラメーターを持つ Genie 2 で同様の現象をで観察しました。このパターンは、あらゆるアーキテクチャで共通しており、単なる偶然として片付けるのは難しいでしょう。
最近、いくつかの主要プレーヤーがモデルを非公開のままにするのではなく、公開する道を選んでいます。NVIDIA の Cosmos、Meta の V-JEPA 2、Physical Intelligence の pi-zero はいずれも 2025 年にオープンソースとして公開されました。競争の激しい分野では、これは示唆的な動きです。モデルを囲い込むよりも幅広い研究コミュニティに貢献する方が、進歩のためのより良い戦略になりつつあることを示しています。
ただし、モデルの機能が向上した一方で、運用コストは改善していません。テキスト言語モデルのコストは、ユーザー 100 時間あたり約 15 セントです。一方で Sora は ユーザー 1 時間あたり 468 米ドルかかります。より効率的なオプションとされる Odyssey でさえも、セッションごとに 専用 H100 が必要で、費用は 1 時間あたり 50 米ドルに達します。その理由は構造的なもので、動画はリアルタイムでフレームごとに連続的に生成されなければならないからです。テキストモデルのように単一の GPU で 50 人のユーザーを共有することはできません。つまり、ユニットエコノミクスは API 価格というよりもプレミアムクラウドコンピューティングに近いものになっています。
研究段階で、モデルが実現できることと、それをデプロイする際にかかるコストとの間のこのギャップこそが、ラボの成果を実世界に展開するうえで最大の障壁となっています。朗報もあります。このようなコスト曲線は以前にも経験しているからです。LLM 推論コストは 3 年間で約 1000 分の 1 にまで低下し、Decart は既にカスタムビルドのエンジンによって動画のコストを 400 の 1 に削減したと主張しています。とはいえ、これを大規模に実現できる実用レベルの推論システムは、まだ商用製品として存在していません。そのため、これを最初に構築したチームが協力な競争優位を獲得することになるのです。
NVIDIA は、この分野で最も垂直統合されたインフラストラクチャスタックを構築しています。ワールドモデルのトレーニングには Cosmos、物理シミュレーションには Isaac Sim、ヒューマノイド向け基礎モデルには GR00T、デジタルツインには Omniverse、そしてエッジでの VLA 推論には Jetson Thor を用いています。AWS は、これらすべてをトレーニングとデプロイを支えるクラウドレイヤーを提供しています。モデルトレーニングには Amazon SageMaker、大規模シミュレーションとワークロードオーケストレーションには AWS Batch、最適化された推論には AWS Inferentia、エッジフリート管理には AWS IoT Greengrass が使われています。実稼働環境では、物理の忠実度は NVIDIA、トレーニングとデータオーケストレーションにはクラウド、リアルタイム展開には専用シリコンを採用するなど、パターンは一貫しています。
タイムラインを決定する 3 つのギャップ
研究と商用展開の間にあるのは、インフラストラクチャの課題だけではありません。この移行のスピードを左右する、より深い 3 つの構造上の大きなギャップがあります。
1. データのギャップ
1 つ目は、どれだけ動画を使っても埋められないギャップです。動画は捉えるのは見た目であって、触感ではありません。材料の取り扱い、部品の挿入、部品の組み立てなど、触覚を伴う作業では、モデルのパフォーマンスが印象的なレベルから実用にならないレベルへと落ち込みます。なぜでしょうか? トレーニングデータに触覚情報が含まれていないからです。人間の手には約 17,000 個の触覚受容体があることを考えてみてください。実用化されているロボットハンドのほとんどには、触覚センサーがありません。センサー自体は入手可能であるにもかかわらず、大規模で標準化された触覚データセットは現時点で存在しません。 これは資金や技術の失敗ではなく、むしろ連携不足が原因です。どの研究室もこのようなデータセットがあれば恩恵を受けるでしょうが、単独で構築するだけの十分なインセンティブがある研究室はありません。この連携問題を解決する人が、オープンなコンソーシアムであれ、商業的なデータ事業であれ、この分野全体を計り知れないほど加速させることになるでしょう。
2. アーキテクチャのギャップ
今日のほとんどのロボット企業は、模倣学習に依存しています。つまり、タスクを実演し、ロボットにそれを再現させるという方法です。これは単純な作業には有効ですが、予測できない状況では困難になります。UPenn の GRASP Lab が、この方法で訓練されたロボットを真に未知の条件でテストしたところ、成功率はわずか 16.7% にとどまりました。これは、現実世界の条件で求められる信頼性とは程遠い数字です。
ワールドモデルは、これとは異なるアプローチを可能にします。ロボットはシミュレーション内で故障モードを探索し、物理的なリスクなしにエッジケースを何度も検証し、実世界に展開する前に能力を積み上げることができます。人間の介入なしに 10 時間以上連続稼働したロボットの記録がある事例は、すべて模倣学習ではなくこの強化学習を用いています。産業レベルの信頼性を実現するには、単純な模倣を超えて、より堅牢な学習方法へと移行する必要があります。
3.時間的コヒーレンス
動画生成型ワールドモデルは、短時間で説得力のある物理現象をシミュレートできます。長期間にわたって展開すると、一貫性が失われるようになります。物体が本来あるべき場所になかったり、反応を起こすはずのものが反応しなかったりする場合もあります。シミュレーションの実行時間が長くなるほど、エラーが蓄積され、シミュレートされた世界が物理世界と似ても似つかなくなる可能性があります。例えば、Genie 3 は、この種のドリフトが始まるまでのほんの数分間だけ一貫した状態にあります。これはこれらのモデルの設計方法に組み込まれている問題なので、アーキテクチャ上のソリューションが必要です。World Labs の Marble のような他のモデルでは、時間的ドリフトをより適切に処理できますが、これらのモデルはより高価になりがちです。したがって、真の課題は、忠実度の高いシミュレーションと実行コストの適切なバランスを見つけることにあります。
エコシステムのマッピング
ワールドモデルとマルチモーダル AI エコシステム全体で、120 を超える組織をマッピングしました。このドキュメントには、完全版のインタラクティブなネットワーク可視化も含まれています。
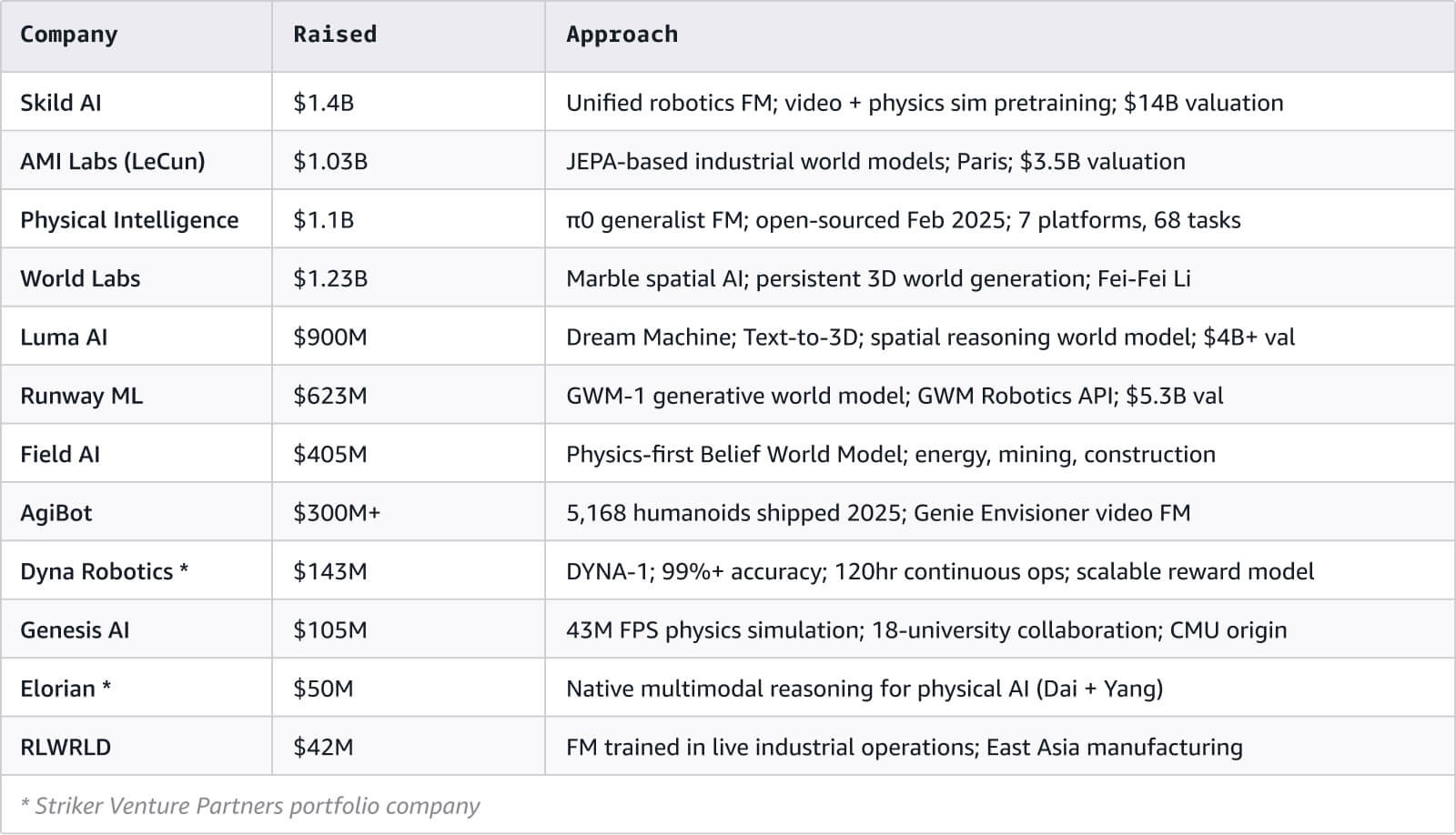
これらの企業を支えている人々の多くは、プロダクトマネージャーではなく研究者であり、学術界を離れて大手テック企業へと移っています。Hafner 氏と Yan 氏は Dreamer シリーズから Embo に移り、Hausman 氏は DeepMind のロボティクスチームを離れて Physical Intelligence を共同創業し、LeCun 氏は Meta AI から AMI Labs に移りました。
こうした研究者が、終身在職権のある研究職や企業の研究室を離れて自らが開発した科学を商業化する方向へ向いているのは大きな変化の兆しです。中核となる科学は、次の論文を書くことで得られる利益よりも、最初の製品を生み出す利益の方が大きくなる段階に達したのです。
どれだけ速く進み、誰が価値をつかむのか?
機械学習におけるあらゆる大きな転換はすべて同じパターンをたどってきました。その一貫性は、もはやトレンドというよりは自然法則に近いものです。学習した表現が、手作業で設計された表現に置き換わるのです。AI がデータから何かを自動的に学習する方法を見つけるたびに、人間がルールを手で書き下す従来の手法は置きかられます。そしてその変化は急速に進んでいます。トランスフォーマーは手実装の文法規則を置き換えましたが、ワールドモデルは今、物理そのものに対して同じことを試みています。手作りのシミュレーターを、インターネット規模の動画でトレーニングされた学習済みモデルに置き換えようとしているのです。
今問われているのは、それが原則として実現するかどうかではなく、どれだけ速く実現するのか、どの課題が先に解決されるのか、そして誰が持続的な価値を獲得するかということです。
アーキテクチャをまたいでスケーリングは明確かつ一貫しており、データの経済性も改善しています。推論コストは依然として高いものの、モデル設計の効率化、より優れたサービスインフラストラクチャ、そして専用の推論ハードウェアの迅速なデプロイといった要因が相まって低下傾向にあります。
市場を支える資本も潤沢です。主要な基盤モデル系スタートアップ企業全体で 30 億米ドル以上を調達しており、ヒューマノイドハードウェアを開発する企業群の企業価値は総計で 500 億米ドルを超えています。
最も重要なレイヤーでありながら、開発が最も遅れているレイヤーは、トレーニング済みモデルを実環境でのデプロイにつなぐインフラストラクチャ、つまりツール群、サービングエンジン、フリート管理システムです。これらのソリューションを構築する企業や創業者は、言語モデルの世界で AWS のようなクラウドプロバイダーが担っているのと同じ立場、つまり、最終的には他のすべてが依存する重要なレイヤーを提供する立場を占めることになるでしょう。

Nikhil Suresh
Nikhil Suresh 氏 は Striker Venture PartnersStriker Venture Partners の投資家で、創業当初から創業者と提携して、AI、インフラストラクチャ、ハードウェアの分野で業界を牽引する企業を築き上げています。スタンフォード大学のスケーリングインテリジェンスラボの元シリアルファウンダーであり AI 研究員でもある Nikhil 氏は、以前は Mercor で初期のエンジニアとして検索と機械学習に取り組んでいました。Nikhil 氏は、潜在能力の高いチームが製品形成の初期段階をナビゲートして、永続的で世代を超えたビジネスを構築できるよう支援することに重点を置いています。

Dhruv Sharma
Dhruv Sharma 氏 は AWS のベンチャーキャピタルおよびスタートアップチームの一員であり、大手ベンチャーキャピタル企業とそのポートフォリオ企業と提携して、特に AI インフラストラクチャとフロンティアテクノロジーを横断して構築、立ち上げ、拡大を行っています。それ以前は、ベンチャーキャピタルと投資銀行業務に 8 年以上携わり、投資を主導し、初期段階から IPO まで、企業の規模拡大を支援してきました。
このコンテンツはいかがでしたか?