Wie war dieser Inhalt?
- Lernen
- Weltmodelle und der multimodale KI-Stack: Die Regeln der Robotik werden neu geschrieben
Weltmodelle und der multimodale KI-Stack: Die Regeln der Robotik werden neu geschrieben

Den größten Teil der Menschheitsgeschichte hindurch haben wir die Welt durch unseren Körper und unseren Tastsinn kennengelernt und begriffen. Wir lernten, dass Feuer brennt, indem wir einer Flamme zu nahe kamen, und wir lernten durch Stürze, dass Eis glatt ist. Dieses Wissen war an den Körper gebunden und entstand aus direkter Erfahrung – es verbreitete sich nur so schnell, wie ein Mensch es erleben, speichern und an andere weitergeben konnte.
Um Wissen in größerem Umfang zu übertragen und zu teilen, mussten wir es formalisieren. Bewegungsgesetze wurden niedergeschrieben, die Thermodynamik wurde kodifiziert und Systeme, die das Verhalten der Welt modellieren, wurden entwickelt. Dieser Ansatz bildete das Fundament der Physik, und drei Jahrhunderte lang waren diese handgefertigten Regeln das einzige Mittel, das wir hatten, um die Welt zu begreifen.
Dann kam die Revolution des maschinellen Lernens, und anstatt Wissen manuell zu kodieren, konnten Systeme darauf trainiert werden, es selbstständig zu erlernen. Handgefertigte Repräsentationen wurden durch erlernte ersetzt – zwar (noch) nicht für die Physik, aber für die Sprache. In dem Moment, als ein auf Internettexten trainiertes Transformer-Modell flüssige, zusammenhängende Prosa generieren konnte, wurden die Grammatikregeln, an denen Sprachwissenschaftler Jahrzehnte gearbeitet hatten, plötzlich hinfällig. Die Kluft zwischen dem alten, manuellen Ansatz und dem neuen Verfahren der erlernten Repräsentationen markierte einen bedeutenden strukturellen Wandel. In weniger als einem Jahrzehnt war das gesamte Gebäude der regelbasierten Computerlinguistik (NLP) in sich zusammengebrochen.
Ein gewaltiger Sprung für die Robotik?
Die Robotik und die physische KI befinden sich heute in exakt derselben Position wie die Sprach-KI im Jahr 2005. Jede Simulation basiert auf manuell kodierter Physik. Jede Kollisionsdynamik, jeder Reibungskoeffizient und jedes Kontaktmodell werden von Ingenieuren festgelegt, die im Grunde Grammatikregeln für die physische Welt schreiben.
Ein Roboter, der in einer dieser Simulationen trainiert wurde, kann in der Umgebung, für die er geschaffen wurde, gute Leistungen erbringen. Probleme entstehen jedoch, wenn man ihn in eine unbekannte Umgebung bringt, wie etwa eine Küche, oder ihn bittet, eine neue Aufgabe auszuführen, wie das Greifen eines Objekts. Dies liegt nicht daran, dass die Simulation schlecht konstruiert war, sondern an strukturellen Fehlern: Man kann sich den Weg zu allgemeiner physischer Intelligenz ebenso wenig durch manuelle Kodierung erschließen, wie man GPT-4 hätte programmieren können. Handkodierte Physik ist nicht auf allgemeine physische Intelligenz skalierbar.
Wenn die Sprach-KI einen so dramatischen Sprung gemacht hat, warum gelingt dies der Robotik nicht? LLMs hatten einen bedeutenden Vorteil: das Internet. Mit Billionen von bereits digitalisierten und praktisch kostenlosen Token hatten LLMs Zugriff auf das größte jemals zusammengestellte Korpus menschlichen Wissens. GPT-4 wurde beispielsweise mit etwa 13 Billionen Token trainiert. Die Robotik verfügt über keine vergleichbare Ressourcenbasis. Jede Roboter-Trajektorie (ein Beispiel für einen Roboter, der eine Aufgabe abschließt) erfordert physische Hardware, menschliche Bediener, reale Umgebungen und eine mühsame Aufbereitung. Der „Open X-Embodiment“-Datensatz, das kombinierte Ergebnis von vierunddreißig Robotiklaboren weltweit, enthält etwa eine Million davon. Diese Lücke zwischen den 13 Billionen Token von GPT-4 und einer Million Trajektorien ist gewaltig und lässt sich nicht durch inkrementelle Investitionen schließen.
Es bedarf eines grundlegend neuen Ansatzes für die Datenerfassung. Und derjenige, der sich gerade abzeichnet – das Training von Robotern mit Internetvideos –, stellt möglicherweise die folgenschwerste architektonische Entscheidung in der Geschichte der physischen KI dar.
Weltmodelle, Weltwissen und neuronale Netzwerke
Ein Weltmodell ist ein neuronales Netzwerk, das physikalische Intuition auf ähnliche Weise wie der Mensch erlernt: durch Beobachtung anstatt durch Formalisierung. Wie lernt ein Kind, dass ein Ball vom Tisch rollen wird? Nicht durch das Lösen des zweiten Newtonschen Gesetzes und auch nicht durch das Ausführen einer physikalischen Simulation. Es beobachtet, und irgendwann weiß es Bescheid.
Ein Weltmodell funktioniert auf dieselbe Weise. Zeigen Sie ihm Millionen von Stunden Videomaterial – Koch-Tutorials, Fabrikhallen, Verkehr, Baustellen – und es wird beginnen, ein internes Bild davon zu entwickeln, wie sich die Welt verhält. Diese Art von implizitem Verständnis ist keine weniger wertvolle Form von Wissen. Sie ist oft verlässlicher als starre Regeln, da sie flexibel ist und auch dort funktioniert, wo ein programmiertes Modell längst scheitern würde. Warum das für die Robotik so wichtig ist? Es geht um den Unterschied zwischen zwei Arten von Wissen.
Weltwissen, wie etwa Beispiele dafür, wie sich Objekte unter Schwerkraft verhalten und wie sich Materialien verändern, ist universell. Es hat nichts mit dem spezifischen Roboter zu tun. Es ist die Physik der Realität selbst; glücklicherweise ist das Internet für die Robotik-Entwicklung eine nahezu unerschöpfliche Videoquelle für genau diese Phänomene.
Handlungswissen, also die Art und Weise, wie ein spezifischer Roboter Befehle in physische Bewegungen umsetzt, ist hardwarespezifisch und muss aus roboterspezifischen Daten erlernt werden. Die in den letzten zwei Jahren gesammelten Forschungsergebnisse haben eine entscheidende Erkenntnis geliefert: Man benötigt nur sehr wenig Handlungswissen, sobald eine starke Basis an Weltwissen vorhanden ist.
Betrachten wir zwei aktuelle Ergebnisse, die dies in der Praxis veranschaulichen. Zuerst Metas V-JEPA 2: Das Weltmodell wurde mit über einer Million Stunden Internetvideo trainiert und erhielt anschließend lediglich 62 Stunden unbeschriftetes Robotervideo ohne aufgabenspezifisches Training. Es erreichte eine Zero-Shot-Erfolgsquote von 80 Prozent bei Pick-and-Place-Aufgaben in Laboren, die es zuvor nie gesehen hatte.
Zweitens, DeepMinds Dreamer 4. Der KI-Agent lernte, in dem Spiel Minecraft Diamanten zu sammeln, was 20 000 aufeinanderfolgende Entscheidungen auf Basis roher Pixel erforderte – und das ganz ohne jegliche Interaktion mit der Umgebung. Beide Beispiele deuten auf dieselbe zugrunde liegende Dynamik hin: Das Verständnis darüber, wie die physische Welt funktioniert, kann durch das riesige Angebot an bereits existierenden Internetvideos erreicht werden. Die roboterspezifischen Daten, die spärlich vorhanden sind, müssen lediglich das viel kleinere Problem abdecken, wie sich diese spezielle Maschine bewegt. Die Herausforderung der Datenknappheit, welche die Robotik jahrelang gebremst hat, lässt sich plötzlich weitaus besser bewältigen.
Fünf Architekturen, eine offene Frage
Der Begriff „Weltmodell“ wird weitläufig verwendet. In der Praxis herrscht tiefgreifende Uneinigkeit darüber, was eine physische Repräsentation eigentlich bedeutet. Fünf Architekturen haben sich herauskristallisiert, die jeweils auf einer anderen Theorie darüber basieren, wie physische Systeme in einem lernenden System kodiert werden sollten. Sie sind sich einig, dass handkodierte Simulationen unzureichend sind. In fast allen anderen Punkten sind sie uneins.
Videogenerative Modelle verfolgen den direktesten Ansatz. Modelle wie Nvidias Cosmos und Runways GWM-1 funktionieren beide durch die Vorhersage künftiger Einzelbilder unter der Bedingung, dass eine spezifische Handlung stattgefunden hat. Dies basiert auf der Vorstellung, dass Videos genügend Informationen über die physische Welt erfassen, um Roboter damit trainieren zu können. Der Nachteil hierbei ist die Effizienz, da das Modell erhebliche Ressourcen verbraucht, um jedes Pixel in einem Bild vorherzusagen – einschließlich jener, die für die Aufgabe irrelevant sind. DeepMinds Genie 3 treibt dies am weitesten voran. Mit 24 Bildern pro Sekunde ist es das erste Weltmodell, das in Echtzeit arbeitet und als live spielbare Simulation fungiert.
Modelle in latenter Umgebung haben einige der bedeutendsten Ergebnisse hervorgebracht. Danijar Hafner und Timothy Lillicrap von DeepMind entwickelten beispielsweise die Dreamer-Serie basierend auf einer einfachen Idee. Anstatt vorherzusagen, wie das nächste Video-Einzelbild aussehen wird, erstellt das Modell eine vereinfachte interne Zusammenfassung des aktuellen Weltzustands und nutzt diese, um zu simulieren, was als Nächstes passiert. Dies ist weitaus effizienter und hat eindrucksvolle Ergebnisse geliefert:
- Dreamer V2 war der erste Agent, der durch ein Weltmodell eine Leistung auf menschlichem Niveau bei Atari-Spielen erreichte.
- Dreamer V3 übertraf spezialisierte Methoden in über 150 Aufgabenstellungen ohne jegliche aufgabenspezifische Feinabstimmung.
- Dreamer 4 wurde vollständig auf Basis von vorab aufgezeichneten Daten trainiert, ohne jegliche Interaktion mit einer Live-Umgebung.
JEPA (Yann LeCuns Joint Embedding Predictive Architecture) sagt abstrakte Repräsentationen anstelle von Pixeln voraus. Dies basiert auf der Vorstellung, dass ein abstraktes, konzeptionelles Verständnis der Welt für physikalische Schlussfolgerungen effektiver ist als rohe visuelle Informationen. V-JEPA 2 erreichte eine Zero-Shot-Erfolgsquote von 80 Prozent bei Manipulationsaufgaben ausschließlich unter Verwendung von Internetvideos. LeCun unterstützt diesen Ansatz so konsequent, dass er die AMI Labs in Paris gründete, die 1,03 Milliarden US-Dollar bei einer Bewertung von 3,5 Milliarden US-Dollar generierten, noch bevor sie ein einziges Produkt ausgeliefert hatten.
Natives multimodales Reasoning basiert auf der Idee, dass ein KI-System Text, Bilder, Video und Audio von Grund auf gemeinsam verarbeiten muss und nicht als separate, nachträglich zusammengefügte Komponenten. Die anderen vier Architekturen gehen davon aus, dass man ein für Text entwickeltes System nehmen und dieses um physikalisches Verständnis ergänzen kann. Natives multimodales Reasoning lehnt dies ab mit dem Argument, dass das Nachrüsten von physikalischem Verständnis bei textfokussierten Systemen eine unüberwindbare Obergrenze für deren Leistungsfähigkeit schafft. Elorian, mitbegründet von Andrew Dai und Yinfei Yang, baut auf dieser These auf. Striker Partners führte die Co-Seed-Runde an.
Diffusionsbasierte Weltmodelle können als universelle, erlernte Simulatoren fungieren, die präzise Umgebungen vollständig aus der Dynamik generieren. Das agentische KI-Modell DIAMOND erreichte die höchste menschen-normalisierte Punktzahl aller Weltmodelle im Atari-100k-Benchmark. UniSim demonstrierte, dass ein einzelnes diffusionsbasiertes Modell simulieren kann, wie sowohl Menschen als auch Roboter mit der physischen Welt interagieren. Von den fünf Architekturen sind diffusionsbasierte Modelle im Bereich der realen Robotik am wenigsten erprobt.
Es bleibt offen, ob ein Paradigma dominieren wird oder ob die fünf allmählich zu etwas Neuem verschmelzen. Erkenntnisse aus den letzten 18 Monaten deuten auf eine Hybridisierung hin. Physikalisches Verständnis zeichnet sich bei allen fünf Architekturen mit zunehmender Skalierung ab, und die Kluft zwischen ihnen verringert sich. Am Ende entscheidet wohl nicht die Architektur, sondern welches Team es am schnellsten schafft, aus der Forschung ein fertiges Produkt zu machen.
Skalierung funktioniert. Die Wirtschaftlichkeit hingegen nicht.
Das Feld schreitet rasant voran. Die Parameter der Weltmodelle haben sich in fünf Jahren etwa tausendfach vervielfacht, von den zwei Millionen bei PlaNet bis zu den 14 Milliarden bei Cosmos. Die Trainingsläufe konkurrieren mittlerweile mit den größten Sprachmodell-Bestrebungen: Cosmos beanspruchte drei Monate lang 10 000 H100-GPUs. Bei dieser Größenordnung beginnt etwas Interessantes zu passieren.
Das Verständnis der physischen Welt beginnt sich als unbeabsichtigter Nebeneffekt der Skalierung abzuzeichnen. Die Modelle wurden nicht darauf programmiert, Ursache und Wirkung in der physischen Welt zu verstehen; stattdessen haben sie es selbstständig erschlossen. OpenAI beobachtete dies beispielsweise bei Sora, als 3D-Konsistenz, Objektpermanenz und realistische Physik als Folge von Skalierungseigenschaften im Modell auftraten. DeepMind machte dieselbe Beobachtung bei Genie 2 mit 11 Milliarden Parametern. Dieses Muster hielt über jede Architektur hinweg an, was es schwierig macht, es als bloßen Zufall abzutun.
Mehrere große Akteure haben sich vor Kurzem dazu entschieden, ihre Modelle öffentlich freizugeben, anstatt sie privat zu halten. Nvidias Cosmos, Metas V-JEPA 2 und Physical Intelligences pi-zero wurden im Jahr 2025 alle als Open Source veröffentlicht. In diesem wettbewerbsintensiven Sektor ist das ein deutliches Signal: Der Beitrag zu einer breiten Forschungsgemeinschaft stellt eine bessere Strategie für den Fortschritt dar, als die Modelle hinter verschlossenen Türen zu halten.
Doch während sich die Leistungsfähigkeit der Modelle verbessert hat, sind die Kosten für deren Betrieb nicht gesunken. Ein textbasiertes Sprachmodell kostet etwa 15 Cent pro hundert Benutzerstunden. Sora kostet 468 USD pro Benutzerstunde. Selbst Odyssey, eine der effizienteren Optionen, benötigt immer noch eine dedizierte H100 pro Sitzung für 50 USD pro Stunde. Der Grund ist strukturell, da Video kontinuierlich, in Echtzeit und Bild für Bild generiert werden muss. Man kann nicht 50 Benutzer auf eine einzige GPU verteilen, wie es bei Textmodellen möglich ist, was bedeutet, dass die Stückkosten eher denen von Premium-Cloud-Computing als denen von API-Preisen entsprechen.
Diese Kluft zwischen der Leistungsfähigkeit der Modelle in der Forschung und den Kosten für ihren Betrieb ist das größte Hindernis zwischen Laborergebnissen und dem realen Einsatz. Die gute Nachricht? Wir haben eine solche Kostenkurve schon einmal erlebt. Die Kosten für die LLM-Inferenz fielen in drei Jahren um etwa das Tausendfache und Decart vermeldet bereits eine 400-fache Effizienzsteigerung für Video durch eine maßgeschneiderte Engine. Die produktionsreifen Inferenzsysteme, die dies im großen Maßstab liefern werden, existieren noch nicht als kommerzielle Produkte. Daher werden die Teams, die sie als Erste entwickeln, einen starken Wettbewerbsvorteil erlangen.
NVIDIA hat den am stärksten vertikal integrierten Infrastruktur-Stack in diesem Bereich zusammengestellt: Cosmos für das Training von Weltmodellen, Isaac Sim für die Physiksimulation, GR00T für humanoide Basismodelle, Omniverse für digitale Zwillinge und Jetson Thor für die VLA-Inferenz am Edge. AWS stellt die Cloud-Ebene bereit, auf der all dies trainiert und implementiert wird: Amazon SageMaker für das Modelltraining, AWS Batch für groß angelegte Simulationen und Workload-Orchestrierung, AWS Inferentia für optimierte Inferenz und AWS IoT Greengrass für das Flottenmanagement am Edge. Im produktiven Betrieb ist das Muster konsistent: NVIDIA für die physikalische Genauigkeit, die Cloud für Training und Datenorchestrierung sowie spezialisierte Halbleiter für den Echtzeit-Einsatz.
Drei Lücken, die den Zeitplan bestimmen
Die infrastrukturelle Herausforderung ist nicht das einzige Hindernis, das zwischen der Forschung und dem kommerziellen Einsatz steht. Es gibt drei tiefere, strukturelle Lücken, die bestimmen werden, wie schnell dieser Übergang erfolgt.
1. Die Datenlücke
Die erste Lücke ist eine, die auch durch noch so viel Videomaterial nicht geschlossen werden kann. Videos erfassen, wie Dinge aussehen, nicht wie sie sich anfühlen. Aufgaben, die Berührung erfordern – wie die Handhabung von Materialien, das Einsetzen von Komponenten oder das Zusammenbauen von Teilen –, führen zu einem Abfall der Modellleistung von beeindruckend zu unbrauchbar. Warum? Es gibt keine taktilen Informationen in den Trainingsdaten. Bedenken Sie, dass eine menschliche Hand 17 000 Berührungsrezeptoren enthält. Die meisten eingesetzten Roboterhände hingegen besitzen keinerlei taktische Sensoren. Obwohl die Sensoren selbst verfügbar sind, existiert derzeit kein standardisierter taktiler Datensatz in großem Maßstab. Dies ist kein Versagen von Finanzierung oder Technologie, sondern vielmehr ein Versagen der Koordination. Jedes Labor würde von einem solchen Datensatz profitieren, aber keines hat genug Anreiz, ihn allein aufzubauen. Wer dieses Koordinationsproblem löst – sei es durch ein offenes Konsortium oder ein kommerzielles Datenprojekt –, beschleunigt das gesamte Feld in einem Maße, das man kaum überbewerten kann.
2. Die architektonische Lücke
Die meisten Robotikunternehmen verlassen sich heute auf Imitationslernen: Eine Aufgabe wird demonstriert und der Roboter repliziert diese. Dies funktioniert für einfache Aufgaben, stößt jedoch in unvorhersehbaren Situationen an Grenzen. Als das GRASP Lab der UPenn auf diese Weise trainierte Roboter unter völlig neuen Bedingungen testete, verzeichnete es eine Erfolgsquote von lediglich 16,7 Prozent – weit weg von der Zuverlässigkeit, die reale Bedingungen erfordern.
Weltmodelle bieten einen anderen Ansatz. Ein Roboter kann Fehlermodi in der Simulation untersuchen, Grenzfälle ohne physisches Risiko durchlaufen und Kompetenz aufbauen, bevor er in der realen Welt eingesetzt wird. Jeder dokumentierte Fall, in dem ein Roboter kontinuierlich 10 Stunden oder länger ohne menschliches Eingreifen gearbeitet hat, nutzte dieses Reinforcement Learning anstelle von Imitationslernen. Um eine industrielle Zuverlässigkeit zu erreichen, müssen wir über das einfache Imitieren hinaus zu robusteren Lernmethoden übergehen.
3. Temporale Kohärenz
Videogenerative Weltmodelle können über kurze Zeiträume eine überzeugende Physik simulieren. Über längere Zeiträume gestreckt, werden sie jedoch inkonsistent. Objekte landen möglicherweise an der falschen Stelle oder etwas, das eine Reaktion auslösen sollte, tut dies nicht. Je länger die Simulation läuft, desto mehr können sich Fehler summieren, bis die simulierte Welt nicht mehr der physischen entspricht. Genie 3 beispielsweise ist nur für wenige Minuten kohärent, bevor diese Art von Drift einsetzt. Es ist ein Problem, das in der Konstruktion dieser Modelle verankert ist und daher eine architektonische Lösung erfordert. Andere Modelle wie Marble von World Labs können den zeitlichen Drift besser bewältigen, sind aber tendenziell teurer. Die eigentliche Herausforderung liegt daher darin, das richtige Gleichgewicht zwischen hochgradig originalgetreuen Simulationen und den Kosten für deren Betrieb zu finden.
Kartierung des Ökosystems
Wir haben über 120 Akteure im Ökosystem der Weltmodelle und der multimodalen KI abgebildet. Die vollständige interaktive Netzwerkvisualisierung ist diesem Dokument beigefügt.
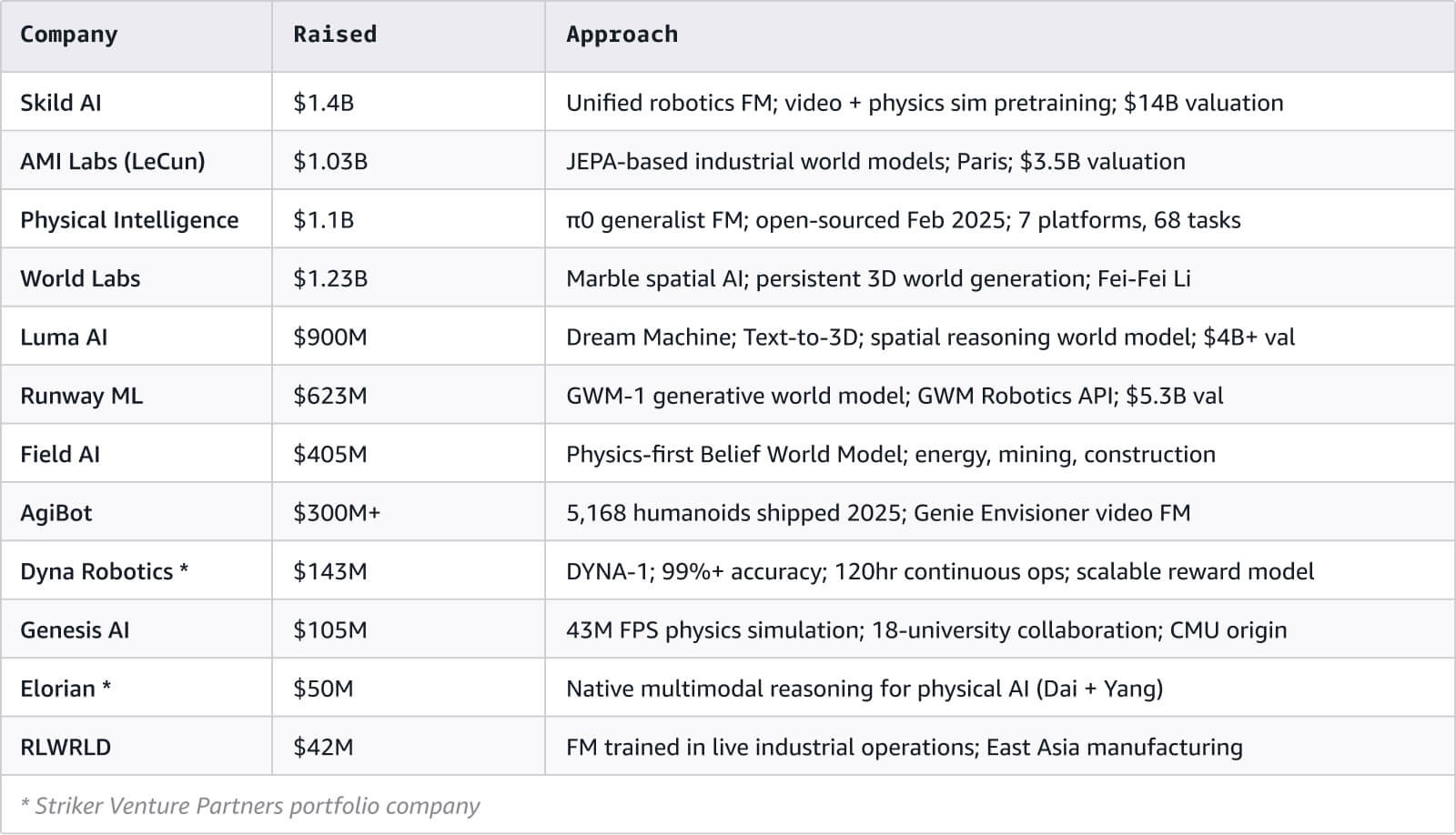
Viele der Köpfe hinter diesen Unternehmen sind Forscher, keine Produktmanager, und haben die akademische Welt verlassen, um sich großen Technologiemarken anzuschließen. Hafner und Yan wechselten von der Dreamer-Serie zu Embo, Hausman verließ das Robotik-Team von DeepMind, um Physical Intelligence mitzugründen, und LeCun wechselte von Meta AI zu AMI Labs.
Die Bereitschaft dieser Forscher, ihre festen Professuren und betrieblichen Forschungslabore zu verlassen, um die von ihnen entwickelte Wissenschaft zu kommerzialisieren, signalisiert einen bedeutenden Wandel. Die Grundlagenforschung ist über den Punkt hinaus gereift, an dem der Ertrag der nächsten wissenschaftlichen Arbeit den Ertrag des ersten Produkts übersteigt.
Wie schnell erfolgt die Entwicklung und wer schöpft den Wert ab?
Jeder bedeutende Übergang im Bereich des maschinellen Lernens ist demselben Muster gefolgt – einem Muster, das so beständig ist, dass es eher einem Naturgesetz als einem bloßen Trend gleicht. Erlernte Repräsentationen ersetzen handgefertigte. Jedes Mal, wenn die KI einen Weg findet, etwas automatisch aus Daten zu lernen, löst dies den alten Ansatz ab, bei dem Menschen die Regeln manuell kodieren; und das geschieht schnell. Transformer haben dies bei handkodierten Grammatikregeln getan, und Weltmodelle versuchen nun dasselbe für die Physik selbst, indem sie handgebaute Simulatoren durch erlernte Modelle ersetzen, die mit Videos im Internet-Maßstab trainiert wurden.
Die Frage ist heute nicht mehr, ob dies prinzipiell geschieht, sondern wie schnell es erfolgt. Es geht darum, welche Herausforderungen zuerst gelöst werden und wer langfristige Werte schöpft.
Die Skalierung verläuft über alle Architekturen hinweg klar und konsistent, und die Datenökonomie verbessert sich. Die Inferenzkosten sind zwar nach wie vor hoch, sinken jedoch aufgrund einer Kombination aus effizienteren Modelldesigns, einer besseren Bereitstellungsinfrastruktur und dem schnellen Einsatz spezialisierter Inferenz-Hardware.
Es steht zudem reichlich Kapital zur Unterstützung des Marktes zur Verfügung: Über 3 Milliarden USD wurden für die führenden Start-ups im Bereich der Basismodelle aufgebracht, und die Unternehmen, die humanoide Hardware entwickeln, werden insgesamt mit über 50 Milliarden USD bewertet.
Die wichtigste und am wenigsten entwickelte Ebene ist die Infrastruktur, die trainierte Modelle mit realen Einsätzen verbindet: das Tooling, die Serving-Engines und die Flottenmanagementsysteme. Die Unternehmen und Gründer, die diese Lösungen entwickeln, werden dieselbe Position einnehmen, die Cloud-Anbieter wie AWS in der Welt der Sprachmodelle innehaben: Sie stellen die entscheidende Basis bereit, von der letztlich alles andere abhängt.

Nikhil Suresh
Nikhil Suresh ist Investor bei Striker Venture Partners, wo er von Anfang an mit Gründern zusammenarbeitet, um wegweisende Unternehmen in den Bereichen KI, Infrastruktur und Hardware aufzubauen. Als ehemaliger Seriengründer und KI-Forscher am Scaling Intelligence Lab der Stanford University war Nikhil zuvor als einer der ersten Ingenieure bei Mercor tätig und arbeitete dort an den Bereichen Suche und maschinelles Lernen. Nikhil konzentriert sich darauf, vielversprechenden Teams dabei zu helfen, die Produktentwicklung in der Frühphase zu meistern, um nachhaltige, generationenübergreifende Unternehmen aufzubauen.

Dhruv Sharma
Dhruv Sharma ist Teil des Teams für Risikokapital und Startups bei AWS, wo er mit führenden Risikokapitalgesellschaften und deren Portfoliounternehmen zusammenarbeitet, um Unternehmen aufzubauen, auf den Markt zu bringen und zu skalieren – insbesondere in den Bereichen KI-Infrastruktur und Zukunftstechnologien. Zuvor war er über acht Jahre lang im Bereich Risikokapital und Investmentbanking tätig, wo er Investitionen leitete und Unternehmen dabei unterstützte, von der Frühphase bis zum Börsengang zu skalieren.
Wie war dieser Inhalt?