이 콘텐츠는 어떠셨나요?
- 학습
- 월드 모델 및 멀티모달 AI 스택: 로보틱스 규칙 재작성
월드 모델 및 멀티모달 AI 스택: 로보틱스 규칙 재작성

인류 역사의 대부분 동안 우리는 몸과 촉각을 통해 세상을 배우고 이해했습니다. 불꽃에 너무 가까이 갔다가 데이면서 불이 뜨겁다는 것을 배웠고, 넘어지면서 얼음은 미끄럽다는 것도 배웠습니다. 그 지식은 우리 몸에 체화되었고, 직접적인 경험을 통해 얻어졌으며, 한 사람이 그것을 경험하고 축적해 다른 사람에게 전달할 수 있는 속도만큼만 확산될 수 있었습니다.
지식을 더 널리 전달하고 공유하려면 데이터를 정형화해야 했습니다. 이에 운동 법칙을 기록하고, 열역학을 체계화했으며, 세상이 어떻게 작동하는지를 모델링하는 시스템을 구축했습니다. 이 접근 방식은 물리학의 기초를 만들었고, 3세기 동안 이러한 수작업으로 만든 규칙들이 우리가 세상을 이해할 수 있는 유일한 수단이었습니다.
그러다가 기계 학습 혁명이 일어났습니다. 지식을 수동으로 인코딩하는 대신 시스템이 지식을 학습하도록 훈련할 수 있게 되었습니다. 직접 작성했던 표현은 학습된 표현으로 대체되었습니다. (아직은) 물리학이 아니라 언어를 위한 표현이었습니다. 인터넷에서 가져온 텍스트를 기반으로 학습한 변환 모델이 유창하고 일관된 문장을 만들어내는 순간, 언어학자들이 수십 년 동안 기록해 왔던 문법 규칙이 갑자기 무용지물이 되었습니다. 손으로 직접 만든 기존의 접근 방식과 학습된 표현을 사용하는 새로운 접근 방식 사이의 격차는 구조적 변화를 불러일으켰고, 10년도 채 되지 않아 규칙 기반 NLP의 전체 구조가 무너졌습니다.
로보틱스의 대도약?
오늘날의 로보틱스와 물리 AI는 2005년 당시의 언어 AI와 정확히 같은 위치에 있습니다.모든 시뮬레이션은 손으로 코딩한 물리학을 기반으로 합니다. 모든 충돌 역학, 모든 마찰 계수, 모든 접촉 모델은 사실상 물리적 세계에 대한 문법 규칙을 작성하는 엔지니어에 의해 지정됩니다.
이러한 시뮬레이션 중 하나에서 학습된 로봇은 자신이 만들어진 환경에서는 잘 작동할 수 있습니다. 하지만 주방과 같은 익숙치 않은 환경에 두거나, 물체를 집는 것과 같은 새로운 작업을 수행하도록 하면 문제가 발생합니다. 시뮬레이션이 잘못 만들어졌기 때문이 아니라 구조적인 한계 때문입니다. 일반 물리 지능을 수작업으로 코딩해서 만들어낼 수는 없으며, 이는 GPT-4를 수작업 코딩으로 만들 수 없는 것과 마찬가지입니다. 수작업으로 작성된 물리 법칙만으로는 일반적인 물리 지능으로 확장할 수 없습니다.
언어 AI가 그렇게 극적인 도약을 이루었다면 왜 로보틱스는 그렇지 못할까요? LLM에는 중요한 이점이 있었습니다. 바로 인터넷이었습니다. 이미 디지털화되어 거의 무료인 수조 개의 토큰을 보유한 LLM은 지금까지 수집된 최대 규모의 인간 지식 코퍼스에 액세스할 수 있었습니다. 예를 들어 GPT-4 모델은 약 13조 개의 토큰으로 훈련되었습니다. 로보틱스에는 이에 상응하는 리소스 기반이 없습니다. 모든 로봇 궤적(로봇이 작업을 완료하는 인스턴스)에는 물리적 하드웨어, 작업자, 실제 환경, 힘든 큐레이션 작업이 요구됩니다. 전 세계 34개 로봇 연구소의 결과를 집약한 Open X-Embodiment 데이터세트조차도 약 100만 개 수준에 불과합니다. GPT-4의 토큰 1,300만 개와 100만 개의 궤적 간의 격차는 엄청나며, 점진적 투자로는 이를 메울 수 없습니다.
완전히 새로운 데이터 수집 접근 방식이 필요합니다. 최근 떠오르고 있는 기술인 인터넷 영상을 이용한 로봇 학습은 물리 AI 역사상 가장 중대한 아키텍처 관련 결정 사항일 수 있습니다.
월드 모델, 세계 지식 및 신경망
월드 모델은 인간과 유사하게, 정형화가 아니라 관찰을 통해 물리적 직관을 학습하는 신경망입니다. 아이는 공이 테이블에서 떨어질 것이라는 사실을 어떻게 배울까요? 뉴턴의 제2법칙을 풀어서도 아니고, 물리 시뮬레이션을 돌려서도 아닙니다. 그저 관찰하다가 결국에는 알게 됩니다.
월드 모델도 같은 방식으로 작동합니다. 요리 튜토리얼, 공장 현장, 교통 상황, 건설 현장 등의 영상 수백만 시간 분량을 보여주면, 세상이 어떻게 작동하는지에 대한 내부적인 그림을 형성하기 시작합니다. 이러한 암묵적 이해는 덜 가치 있는 지식 형태가 아니라, 오히려 더 신뢰할 수 있는 경우가 많습니다. 더 유연하며, 어떤 수작업 모델도 미리 예측하지 못한 상황에서도 잘 작동하기 때문입니다. 이것이 로보틱스에 왜 중요할까요? 이는 두 가지 유형의 지식 간의 구분으로 이어집니다.
중력 하에서 물체가 어떻게 운동하고 물질이 어떻게 변하는지에 대한 예와 같은 세계 지식은 보편적입니다. 특정 로봇과는 아무 상관이 없습니다. 현실의 물리학 그 자체입니다. 다행스럽게도 로봇이 발전하면서 인터넷에는 이를 정확히 보여주는 영상으로 가득 차게 되었습니다.
특정 로봇이 명령을 물리적 움직임으로 변환하는 방법인 행동 지식은 하드웨어별로 다르며, 로봇 전용 데이터로 학습해야 합니다. 지난 2년간 수집한 연구를 통해 중요한 인사이트를 얻을 수 있었습니다. 즉, 일단 강력한 세계 지식을 갖추면 행동 지식이 거의 필요 없다는 것입니다.
이를 실제로 보여주는 두 가지 최근 결과를 살펴보겠습니다. 먼저 Meta의 V-JEPA 2가 있습니다. 이 월드 모델은 100만 시간 이상의 인터넷 영상을 기반으로 훈련된 후, 작업별 훈련 없이 62시간 분량의 레이블이 지정되지 않은 로봇 영상만 제공받았습니다. 그 결과, 이전에 한 번도 본 적 없는 실험실 환경에서 수행된 집기 및 배치 작업에서 제로샷 기준 약 80%의 성공률을 달성했습니다.
둘째, DeepMind의 Dreamer 4.AI 에이전트는 Minecraft 게임에서 다이아몬드를 수집하는 법을 배웠습니다. 그러려면 환경적 상호 작용 없이 원시 픽셀에서 2만 개의 순차적인 결정을 내려야 했습니다. 두 사례 모두 동일한 기본 역학을 보여줍니다. 이미 존재하는 방대한 양의 인터넷 영상을 사용하여 실제 세계가 어떻게 작동하는지 이해할 수 있다는 것입니다. 로봇 관련 데이터는 거의 없지만 특정 기계가 어떻게 움직이는지에 대한 훨씬 작은 문제만 다루면 됩니다. 수년 동안 로보틱스의 발목을 잡았던 데이터 부족 문제가 갑자기 쉽게 해결되었던 것습니다.
다섯 가지 아키텍처, 해결되지 않은 하나의 질문
'월드 모델'이라는 용어는 느슨하게 적용됩니다. 실제로, 주요 접근법들 사이에는 물리적 표현이 무엇을 의미하는지에 대한 의견차가 큽니다. 다섯 가지 아키텍처가 등장했는데, 각 아키텍처는 학습된 시스템에서 물리 시스템을 인코딩하는 방법에 대한 서로 다른 이론을 기반으로 합니다. 이들은 손으로 코딩한 시뮬레이션으로는 충분하지 않다는 데 동의하지만, 다른 거의 모든 부분에서 의견이 서로 다릅니다.
비디오 생성 모델은 가장 직접적인 접근 방식을 취합니다. NVIDIA의 Cosmos와 Runway의 GWM-1 같은 모델은 모두 특정 조치가 취해진 상황에서 미래 프레임을 예측하는 방식으로 작동합니다. 이는 영상이 로봇을 훈련시킬 수 있을 만큼 물리적 세계에 대한 정보를 충분히 담아낸다는 아이디어에 기반합니다. 이 모델의 단점은 효율성입니다. 작업과 무관한 픽셀이 포함되어 있어 프레임의 모든 픽셀을 예측하는 데 상당한 리소스가 사용되기 때문입니다. DeepMind의 Genie 3는 이 부분에서 가장 큰 발전을 이루었습니다. 초당 24프레임으로 실행되는 이 모델은 실시간으로 작동하며 재생 가능한 라이브 시뮬레이션으로 작동하는 최초의 세계 모델입니다.
잠복 공간 모델은 가장 중요한 결과 중 일부를 만들어 냈습니다. 일례로, DeepMind의 Danijar Hafner와 Timothy Lillicrap은 단순한 아이디어를 바탕으로 Dreamer 시리즈를 개발했습니다. 이 모델은 다음 비디오 프레임이 어떻게 보일지 예측하는 대신 세계의 현재 상태를 단순하게 내부 요약한 후 이를 사용하여 다음에 어떤 일이 벌어질지 시뮬레이션합니다. 이는 훨씬 더 효율적이며 몇 가지 인상적인 결과를 가져왔습니다.
- Dreamer V2는 월드 모델을 통해 Atari에서 인간 수준의 성능을 구현한 최초의 에이전트였습니다.
- Dreamer V3는 150개 이상의 작업에서 작업별 튜닝 없이 특화된 방법들을 능가하는 성능을 보였습니다.
- Dreamer 4는 라이브 환경 상호 작용이 전혀 없이, 전적으로 사전 기록된 데이터를 기반으로 학습되었습니다.
JEPA(Yann LeCun의 공동 임베딩 예측 아키텍처)는 픽셀 대신 추상 표현을 예측합니다. 이는 물리적 추론에는 원시 시각적 정보보다는 추상적이고 개념적으로 세상을 이해하는 것이 더 효과적이라는 아이디어에 기반합니다. V-JEPA 2는 인터넷 비디오만 사용한 조작 작업에서 80%의 제로샷 성공률을 달성했습니다. LeCun은 이 접근 방식을 강하게 지지하며, 파리에 AMI Labs를 설립하여 단일 제품을 출하하기도 전에 35억 USD 가치로 10억 3천만 USD의 투자 자금을 확보했습니다.
네이티브 멀티모달 추론은 AI 시스템이 텍스트, 이미지, 비디오, 오디오를 별도의 구성 요소로서 결합하여 처리하는 것이 아니라, 처음부터 함께 처리해야 한다는 아이디어를 바탕으로 합니다. 다른 네 가지 아키텍처에서는 텍스트용으로 구축된 시스템을 사용하고 여기에 물리적인 이해를 더할 수 있다고 가정합니다. 네이티브 멀티모달 추론은 이러한 접근법을 거부하며, 텍스트 중심 시스템에 물리적 이해를 덧붙이는 방식은 달성할 수 있는 성능에 한계를 만든다고 주장합니다. Andrew Dai와 Yinfei Yang는 이 가설을 바탕으로 Elorian을 공동 설립했습니다. 시드 초기 투자 라운드는 Striker Partners가 주도했습니다.
확산 기반 월드 모델은 범용 학습 시뮬레이터로 작동하여 전적으로 역학을 바탕으로 정확한 환경을 생성할 수 있습니다. 에이전틱 AI 모델인 DIAMOND는 Atari 100k에서 월드 모델 중 가장 높은 인간 정규화 점수를 달성했습니다. UniSim은 단일 확산 기반 모델을 통해 인간과 로봇이 물리적 세계와 상호 작용하는 방식을 시뮬레이션할 수 있음을 보여주었습니다. 다섯 가지 아키텍처 중 확산 기반 모델은 실제 로보틱스에서 가장 적게 테스트되었습니다.
하나의 패러다임이 지배적일지 아니면 다섯 가지 패러다임이 점차 새로운 것으로 합쳐질지는 확실치 않습니다. 지난 18개월 동안의 증거에 따르면 하이브리드화가 이루어지는 것으로 추정됩니다. 확장에 따라 5개 아키텍처 모두에서 물리적 이해가 나타나고 있으며, 각 아키텍처 간의 격차가 좁혀지고 있습니다. 이런 상황에서 가장 큰 차별화 요소는 아키텍처가 아닐 수 있습니다. 연구를 프로덕션으로 가장 빠르게 전환할 수 있는 팀이 누구냐의 문제가 될 수 있는 것입니다.
성과를 내고 있는 확장성과 그렇지 못한 경제성
이 분야는 빠른 속도로 발전하고 있습니다. 월드 모델 파라미터는 PlaNet의 2백만 개에서 Cosmos의 140억 개까지 5년 만에 약 천 배로 증가했습니다. 이제 훈련 실행은 언어 모델 관련 최대 규모의 노력에 필적합니다. Cosmos는 3개월 동안 1만 개의 H100 GPU를 소비했습니다. 이 정도 규모에서는 흥미로운 일이 일어나기 시작합니다.
물리 세계에 대한 이해는 규모가 커지면서 의도치 않은 부산물로 나타나기 시작했습니다. 모델들은 물리 세계의 인과관계를 이해하도록 명시적으로 프로그래밍된 것이 아니라, 스스로 그것을 학습해낸 것입니다. 예를 들어 Sora에서 OpenAI는 스케일의 특성에 따라 3D 일관성, 객체 영속성, 현실적인 물리 법칙이 자연스럽게 나타나는 현상을 관찰했습니다. DeepMind 또한 약 110억 개의 파라미터를 가진 Genie 2에서 동일한 현상을 확인했습니다. 이러한 패턴은 거의 모든 아키텍처에서 반복적으로 나타났기 때문에, 단순한 우연으로 치부하기는 어렵습니다.
몇몇 주요 업체들은 최근 모델을 비공개로 유지하는 대신 공개적으로 출시하기로 결정했습니다. NVIDIA의 Cosmos, Meta의 V-JEPA 2, Physical Intelligence의 pi-zero는 모두 2025년에 오픈 소스로 출시되었습니다. 경쟁이 치열한 분야에서는 이러한 현상이 가시적인 신호로, 광범위한 연구 커뮤니티에 기여하는 것이 연구 커뮤니티를 비공개로 유지하는 것보다 발전을 위한 더 나은 전략이 되고 있음을 시사합니다.
그러나 모델의 기능은 향상되었지만 실행 비용은 향상되지 않았습니다. 텍스트 언어 모델의 비용은 사용자 시간 100명당 약 15센트입니다. Sora의 비용은 사용자 시간당 468 USD입니다. 더 효율적인 옵션 중 하나인 Odyssey조차도 세션당 전용 NVIDIA H100이 필요하며 시간당 약 50달러의 비용이 발생합니다. 구조적인 문제에 원인이 있는데, 비디오는 프레임별로 지속적으로 실시간으로 생성되어야 하기 때문입니다. 텍스트 모델처럼 단일 GPU에 50명의 사용자를 분산시킬 수는 없습니다. 즉, 단위 경제성이 API 가격보다 프리미엄 클라우드 컴퓨팅에 더 가깝다는 뜻입니다.
모델이 연구 환경에서 할 수 있는 것과 실제로 이를 실행하는 데 드는 비용 사이의 이 격차는, 실험실 성과와 현실 세계 배포 사이를 가로막는 가장 큰 장애물입니다. 좋은 소식은 이런 비용 곡선을 이전에도 본 적이 있다는 점입니다. LLM 추론 비용은 3년 만에 약 1,000배 감소했으며, Decart는 이미 자체 엔진을 통해 영상 처리 비용을 400배 절감했다고 주장하고 있습니다. 다만 이러한 성능을 대규모로 제공할 수 있는 프로덕션급 추론 시스템은 아직 상용 제품으로 존재하지 않습니다. 따라서 이를 가장 먼저 구축하는 팀이 강력한 경쟁 우위를 차지하게 될 것입니다.
NVIDIA는 이 분야에서 가장 수직적으로 통합된 인프라 스택을 구축했습니다. 월드 모델 학습을 위한 Cosmos, 물리 시뮬레이션을 위한 Isaac Sim, 휴머노이드 파운데이션 모델을 위한 GR00T, 디지털 트윈을 위한 Omniverse, 그리고 엣지 VLA 추론을 위한 Jetson Thor까지 포함됩니다. 한편 AWS는 이 모든 것을 학습하고 배포하는 클라우드 계층을 제공합니다. 모델 학습을 위한 Amazon SageMaker, 대규모 시뮬레이션과 워크로드 오케스트레이션을 위한 AWS Batch, 최적화된 추론을 위한 AWS Inferentia, 엣지 디바이스 관리(플릿 관리)를 위한 AWS IoT Greengrass가 이에 해당합니다. 실제 운영 환경에서는 패턴이 일관되게 나타납니다. 즉, 물리적 정밀도는 NVIDIA가 담당하고, 학습과 데이터 오케스트레이션은 클라우드가 맡으며, 실시간 배포는 목적에 맞게 설계된 전용 실리콘이 담당합니다.
타임라인을 결정짓는 세 가지 격차
연구와 상용 배포 사이의 유일한 문제는 인프라 문제가 아닙니다. 이러한 전환이 얼마나 빨리 진행되는지를 결정하는 세 가지 심층적이고 구조적인 격차가 있습니다.
1. 데이터 격차
첫 번째는 아무리 많은 영상을 사용해도 해결할 수 없는 격차입니다. 영상은 사물이 어떻게 보이는지는 포착하지만, 어떻게 느껴지는지는 담지 못합니다. 재료를 다루거나 부품을 끼우고 조립하는 등 촉각이 중요한 작업에서는 모델 성능이 인상적인 수준에서 사실상 사용할 수 없는 수준으로 떨어집니다. 왜일까요? 학습 데이터에 촉각 정보가 없기 때문입니다. 인간의 손에는 약 1만 7,000개의 촉각 수용기가 존재합니다. 반면 현재 실제로 배치된 대부분의 로봇 손은 촉각 센서를 전혀 갖추지 못하고 있습니다. 센서 자체는 이미 존재하지만, 현재로서는 대규모로 활용 가능한 표준화된 촉각 데이터세트가 없습니다. 이는 자금이나 기술의 실패라기보다 협력의 실패에 가깝습니다. 모든 연구소가 이러한 데이터세트의 혜택을 받을 수 있지만, 단독으로 이를 구축할 충분한 메리트가 없습니다. 오픈 컨소시엄이든 상업적 데이터 전략이든, 이 협력 문제를 해결하는 주체가 등장한다면 그 영향력은 과장하기 어려울 정도로 전체 분야를 가속화할 것입니다.
2. 아키텍처 격차
오늘날 대부분의 로봇 회사는 모방 학습에 의존합니다. 즉, 작업을 시연하고 로봇이 그 작업을 복제하도록 합니다. 이는 간단한 작업에는 효과가 있지만 예측할 수 없는 상황에서는 어려움을 겪습니다. UPenn의 GRASP Lab에서 이러한 방식으로 학습한 로봇을 정말 새로운 환경에서 테스트한 결과 성공률은 16.7%에 불과했는데, 이는 실제 환경에서 요구하는 신뢰성과는 거리가 먼 수치입니다.
월드 모델은 다른 접근 방식을 제공합니다. 로봇은 시뮬레이션 환경에서 실패 사례를 탐색하고, 물리적 위험 없이 다양한 엣지 케이스를 반복적으로 실험하며, 실제 환경에 배포되기 전에 충분한 역량을 축적할 수 있습니다. 인간의 개입 없이 10시간 이상 지속적으로 작동한 모든 로봇 사례는 단순한 모방 학습이 아니라 이러한 강화 학습을 활용해 왔습니다. 산업 수준의 신뢰성을 확보하기 위해서는 단순한 모방을 넘어 보다 견고한 학습 방법으로 발전해야 합니다.
3. 시간적 일관성
비디오 생성 기반 월드 모델은 짧은 시간 동안에는 그럴듯한 물리 시뮬레이션을 만들어낼 수 있습니다. 하지만 이를 더 긴 시간으로 늘리면 점점 일관성이 깨지기 시작합니다. 물체가 잘못된 위치에 나타나거나, 반응이 일어나야 하는 상황에서도 아무 일도 일어나지 않는 식입니다. 시뮬레이션이 길어질수록 이러한 오류는 누적되어, 결국에는 시뮬레이션된 세계가 실제 물리 세계와 더 이상 닮지 않게 됩니다. 예를 들어 Genie 3는 이러한 드리프트가 발생하기 전까지 몇 분 정도만 일관성을 유지할 수 있습니다. 이는 모델 설계 방식에 내재된 문제이기 때문에 아키텍처 차원의 솔루션이 필요합니다. World Labs의 Marble과 같은 다른 모델들은 시간적 드리프트를 더 잘 처리할 수 있지만, 그만큼 비용이 더 높은 경향이 있습니다. 따라서 핵심 과제는 높은 물리적 정밀도와 이를 실행하는 비용 사이에서 적절한 균형을 찾는 데 있습니다.
에코시스템 매핑
저희는 월드 모델과 멀티모달 AI 에코시스템 전반에 걸쳐 120개 이상의 엔터티를 매핑했습니다. 전체 대화형 네트워크 시각화가 이 문서와 함께 제공됩니다.
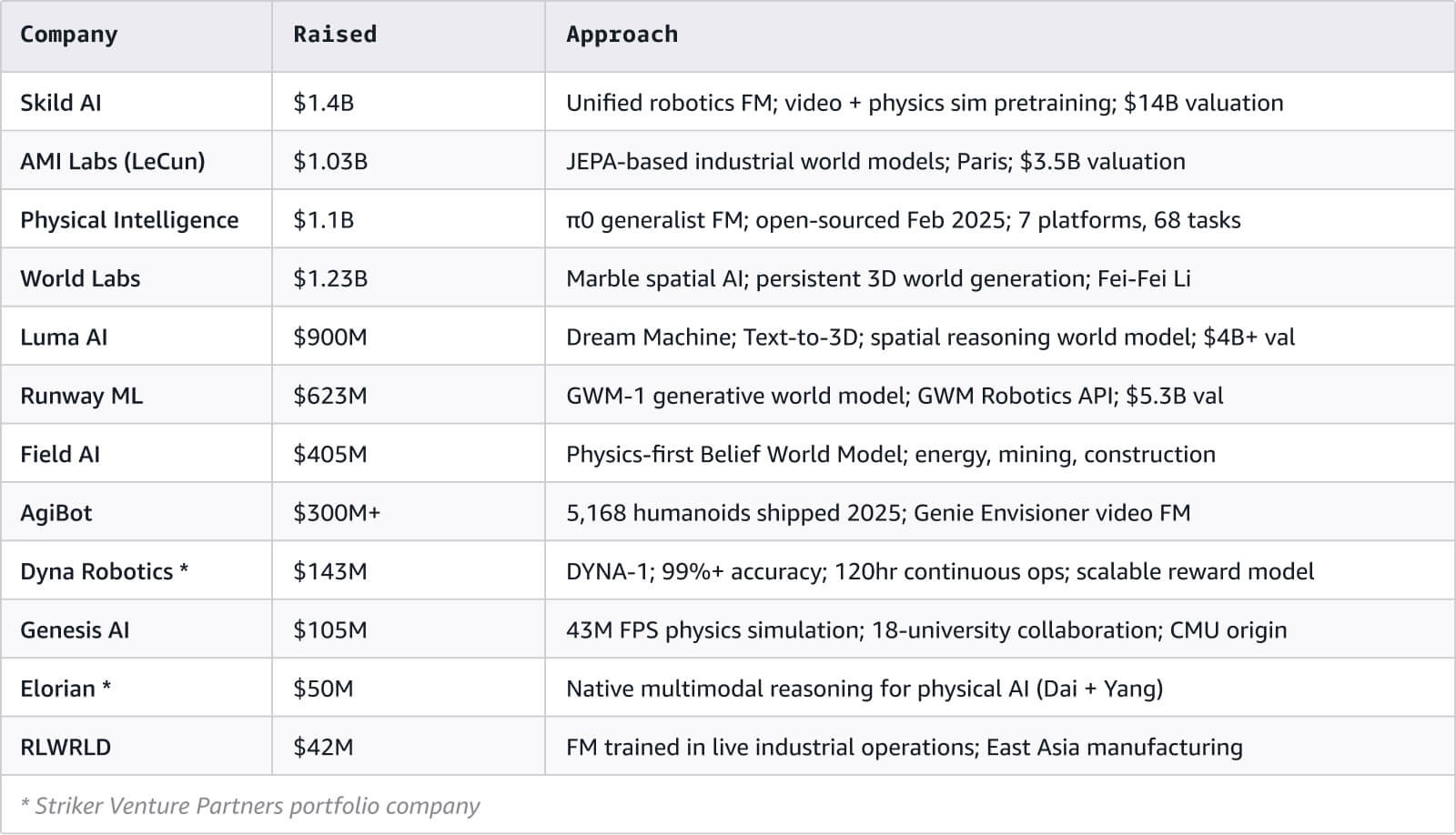
이들 기업을 이끄는 많은 사람들은 제품 관리자라기보다 연구자들이며, 학계를 떠나 빅테크 기업으로 이동해 왔습니다. Danijar Hafner와 Heinrich Yan은 Dreamer 시리즈에서 Embo로 옮겼고, Karol Hausman은 DeepMind의 로보틱스 팀을 떠나 Physical Intelligence를 공동 설립했습니다. Yann LeCun은 Meta AI에서 AMI Labs로 옮겼습니다.
이러한 연구자들이 종신직이나 기업 연구소를 떠나 자신들이 개발한 과학을 상용화하려는 의지를 보인다는 것은 중요한 변화를 시사합니다. 이제 핵심 과학은 다음 논문에서 얻을 수 있는 성과보다 첫 번째 제품에서 얻을 수 있는 가치가 더 큰 단계로 성숙했습니다.
얼마나 빠르게, 그리고 누가 가치를 확보할 것인가?
기계 학습의 모든 주요 전환은 동일한 패턴을 따랐는데, 그 패턴은 너무나 일관적이어서 추세라기보다는 자연 법칙과 유사합니다. 학습된 표현이 수작업으로 만든 표현을 대체합니다. AI가 데이터로부터 무언가를 자동으로 학습하는 방법을 찾을 때마다 사람이 규칙을 수동으로 인코딩하는 기존 접근 방식을 대체합니다. 이는 빠르게 진행되고 있습니다. 트랜스포머는 수작업으로 만든 문법 규칙을 대체했으며, 이제 월드 모델은 인터넷 규모의 영상으로 학습된 모델을 통해 수작업으로 구축된 시뮬레이터를 대체하며 물리 자체에 대해 같은 시도를 하고 있습니다.
이제 문제는 이론적으로 실현 가능한지 여부가 아니라, 얼마나 빨리 실현되는지, 어떤 문제가 먼저 해결되는지, 누가 지속적인 가치를 창출하는지입니다.
확장은 다양한 아키텍처 전반에서 명확하고 일관되게 나타나고 있으며, 데이터의 경제성도 갈수록 개선되고 있습니다. 추론 비용은 여전히 높지만, 더 효율적인 모델 설계, 개선된 서빙 인프라, 특화된 추론용 하드웨어의 빠른 도입이 결합되면서 점차 감소하고 있습니다.
또한 시장을 뒷받침하는 풍부한 자본이 있습니다. 주요 파운데이션 모델 스타트업에서 30억 USD 이상의 자금이 확보되었으며 휴머노이드 하드웨어를 구축하는 회사들의 총 가치는 500억 USD를 넘습니다.
가장 중요한 계층이면서도 가장 덜 발전된 부분은 학습된 모델을 실제 환경에 연결하는 인프라입니다. 툴링, 서빙 엔진, 플릿 관리 시스템이 여기에 해당합니다. 이러한 솔루션을 구축하는 기업과 창업자들은 AWS와 같은 클라우드 제공업체가 언어 모델 생태계에서 차지하는 것과 동일한 위치를 차지하면서, 결국 모든 것이 의존하게 되는 핵심 계층을 제공하게 될 것입니다.

Nikhil Suresh
Nikhil Suresh는 AI, 인프라, 하드웨어 분야에서 창업 초기 단계부터 창업자들과 협력하여 카테고리를 정의하는 기업을 구축하는 데 집중하고 있습니다. Nikhil은 연쇄 창업가 출신으로, 스탠퍼드 대학교 Scaling Intelligence Lab에서 AI 연구원으로 활동했으며, 이전에는 Mercor에서 초기 엔지니어로서 검색과 ML 분야를 담당했습니다. Nikhil은 잠재력이 높은 팀들이 초기 제품 형성 단계에서 올바른 방향을 잡고, 지속 가능한 장기적 기업을 구축할 수 있도록 지원하는 데 주력하고 있습니다.

Dhruv Sharma
Dhruv Sharma는 AWS의 Venture Capital & Startup 팀에 속해 있으며, 주요 벤처 캐피탈 회사 및 포트폴리오 회사와 협력하면서 특히 AI 인프라 및 프론티어 기술 전반을 구축, 출시, 확장하고 있습니다. 이전에는 벤처 캐피털 및 투자 은행에서 8년 이상 근무하면서 초기 단계부터 IPO까지 투자를 주도하고 기업 규모를 확장하는 데 도움을 주었습니다.
이 콘텐츠는 어떠셨나요?