Bagaimana konten ini?
- Pelajari
- Model Dunia dan Tumpukan AI Multimodal: Menulis Ulang Aturan Robotik
Model Dunia dan Tumpukan AI Multimodal: Menulis Ulang Aturan Robotik

Sepanjang sebagian besar sejarah manusia, kami belajar tentang dan memahami dunia melalui tubuh dan indera peraba. Kami belajar bahwa api membakar dengan mendekati nyala api, kami belajar bahwa es itu licin karena terjatuh. Pengetahuan itu diwujudkan, diperoleh melalui pengalaman langsung, serta hanya dapat menyebar secepat seseorang dapat mengalaminya, mengumpulkannya, dan meneruskannya.
Untuk mengirimkan dan berbagi pengetahuan secara lebih luas, kami harus memformalkannya. Hukum gerak ditulis, termodinamika dikodifikasi, dan sistem yang memodelkan bagaimana dunia berperilaku dibangun. Pendekatan ini menciptakan fondasi fisika, serta selama tiga abad aturan buatan tangan ini adalah satu-satunya cara yang kami miliki untuk memahami dunia.
Kemudian muncullah revolusi machine learning, dan alih-alih melakukan enkode pengetahuan secara manual, sistem dapat dilatih untuk mempelajarinya. Representasi yang dibuat secara manual digantikan dengan representasi yang dipelajari, bukan untuk fisika (belum), tetapi untuk bahasa. Saat model transformator yang dilatih pada teks dari internet dapat menghasilkan prosa yang lancar dan koheren, aturan tata bahasa yang telah ditulis oleh ahli bahasa selama puluhan tahun tiba-tiba menjadi usang. Kesenjangan antara pendekatan lama yang dibuat secara manual serta pendekatan baru, dari representasi yang dipelajari, menandai pergeseran struktural yang besar. Dalam waktu kurang dari satu dekade, seluruh bangunan NLP berbasis aturan telah runtuh.
Satu lompatan raksasa untuk robotik?
Robotik dan AI fisik saat ini berada pada posisi yang sama dengan AI bahasa pada tahun 2005. Setiap simulasi dibangun berdasarkan fisika yang dikode secara manual. Setiap dinamika tumbukan, setiap koefisien gesekan, dan setiap model kontak ditentukan oleh para rekayasawan yang, pada dasarnya, menulis aturan tata bahasa untuk dunia fisik.
Robot yang dilatih dalam salah satu simulasi ini dapat beperforma dengan baik untuk lingkungan yang diciptakannya. Namun, masalah muncul, jika Anda membawanya ke lingkungan yang tidak dikenal, seperti dapur, atau memintanya untuk melakukan tugas baru, seperti mengambil suatu objek. Bukan karena simulasi dibangun dengan buruk, tetapi karena kegagalan struktural: Anda tidak dapat membuat kode secara manual ke kecerdasan fisik umum alih-alih Anda dapat membuat kode secara manual dengan GPT-4. Fisika yang dikode secara manual tidak dapat menskalakan kecerdasan fisik umum.
Jika AI bahasa membuat lompatan dramatis seperti itu, mengapa robotik tidak bisa? LLM memiliki keuntungan yang signifikan: internet. Dengan triliunan token, yang sudah digitisasi, dan pada dasarnya gratis, LLM memiliki akses ke korpus pengetahuan manusia terbesar yang pernah dikumpulkan. GPT-4, misalnya, dilatih pada sekitar 13 triliun token. Robotik tidak memiliki basis sumber daya yang setara. Setiap lintasan robot (contoh robot yang menyelesaikan tugas), membutuhkan perangkat keras fisik, operator manusia, lingkungan nyata, dan kurasi yang teliti. Set data Open X-Embodiment, hasil gabungan dari tiga puluh empat laboratorium robotik di seluruh dunia, berisi sekitar satu juta lintasan. Kesenjangan itu, antara 13 juta token GPT-4 versus satu juta lintasan, sangat besar, serta tidak dapat ditutup dengan investasi tambahan.
Diperlukan pendekatan yang sama sekali baru untuk akuisisi data. Salah satu pendekatan yang muncul, melatih robot menggunakan video internet, mungkin mewakili keputusan arsitektural paling penting dalam sejarah AI fisik.
Model dunia, pengetahuan dunia, dan jaringan neural
Model dunia adalah jaringan neural yang mempelajari intuisi fisik dengan cara yang sama seperti yang dilakukan manusia, melalui observasi alih-alih formalisasi. Bagaimana seorang anak belajar bahwa bola akan berguling di meja? Bukan dengan memecahkan hukum kedua dari Newton, atau dengan menjalankan simulasi fisik. Model tersebut mengamati, dan akhirnya ia paham.
Model dunia bekerja dengan cara yang sama. Tunjukkan jutaan jam video, tutorial memasak, lantai pabrik, lalu lintas, konstruksi, dan imodel tersebut akan mulai mengembangkan gambaran internal tentang bagaimana dunia berperilaku. Pemahaman implisit semacam ini bukanlah bentuk pengetahuan yang kurang berharga. Seringkali, pemahaman ini lebih andal, karena lebih fleksibel dan bertahan dalam situasi yang tidak dapat diantisipasi oleh model yang dikode secara manual. Mengapa hal ini penting bagi robotik? Ini bermuara pada perbedaan antara dua jenis pengetahuan.
Pengetahuan dunia, seperti contoh bagaimana objek berperilaku di bawah gravitasi dan bagaimana material berubah, bersifat universal. Hal tersebut tidak ada hubungannya dengan robot tertentu. Ini adalah fisika realitas itu sendiri dan, untungnya bagi perkembangan robotik, internet dipenuhi dengan video yang mendemonstrasikan hal ini secara tepat.
Pengetahuan tindakan, bagaimana robot tertentu menerjemahkan perintah ke dalam gerakan fisik, bersifat khusus perangkat keras dan harus dipelajari dari data khusus robot. Penelitian yang dikumpulkan selama dua tahun terakhir telah memberikan wawasan penting: Anda hanya membutuhkan sedikit pengetahuan tindakan setelah Anda memiliki pengetahuan dunia yang kuat sebagai dasarnya.
Mari kita lihat dua hasil terbaru yang mengilustrasikan hal ini dalam praktiknya. Pertama, V-JEPA 2 dari Meta. Model dunia dilatih pada lebih dari satu juta jam video internet, kemudian hanya diberi 62 jam video robot tanpa label serta tanpa pelatihan khusus tugas. Model ini mencapai 80 persen keberhasilan zero-shot pada tugas pengambilan dan penempatan di seluruh laboratorium yang belum pernah dilihat sebelumnya.
Kedua, Dreamer 4 dari DeepMind. Agen AI ini belajar mengumpulkan berlian di game Minecraft, yang membutuhkan 20.000 keputusan berurutan dari piksel mentah, tanpa interaksi lingkungan apa pun. Kedua contoh menunjukkan dinamika dasar yang sama: pemahaman tentang cara kerja dunia fisik dapat dicapai dengan menggunakan pasokan video internet yang sangat besar yang sudah ada. Data khusus robot, yang langka, hanya perlu mencakup masalah yang jauh lebih kecil tentang bagaimana mesin tertentu itu bergerak. Tantangan kelangkaan data yang telah menghambat robotik selama bertahun-tahun tiba-tiba jauh lebih mudah diatasi.
Lima arsitektur, satu pertanyaan terbuka
Istilah 'model dunia' diterapkan secara umum. Dalam praktiknya, pendekatan utama sangat tidak setuju tentang apa arti representasi fisik. Lima arsitektur telah muncul, masing-masing dibangun berdasarkan teori yang berbeda tentang bagaimana sistem fisik harus dienkode dalam sistem yang dipelajari. Mereka setuju bahwa simulasi yang dikode secara manual tidak cukup. Mereka berbeda pendapat tentang hampir semua hal lainnya.
Model video-generatif mengambil pendekatan paling langsung. Model seperti Cosmos dari NVIDIA dan GWM-1 dari Runway bekerja dengan memprediksi bingkai masa depan, mengingat tindakan tertentu telah terjadi. Ini didasarkan pada gagasan bahwa video mengambil informasi yang cukup tentang dunia fisik untuk dapat melatih robot. Kelemahannya di sini adalah efisiensi, karena model menggunakan sumber daya yang signifikan untuk memprediksi setiap piksel dalam bingkai, termasuk yang tidak relevan dengan tugas. Genie 3 dari DeepMind mendorong hal ini lebih jauh. Berjalan pada 24 bingkai per detik, Genie 3 adalah model dunia pertama yang bekerja secara waktu nyata, berfungsi sebagai simulasi langsung dan dapat dimainkan.
Model ruang laten telah menghasilkan beberapa hasil yang paling signifikan. Danijar Hafner dan Timothy Lillicrap di DeepMind, misalnya, mengembangkan seri Dreamer berdasarkan ide sederhana. Alih-alih memprediksi seperti apa tampilan bingkai video berikutnya, model ini membuat ringkasan internal yang disederhanakan tentang keadaan dunia saat ini dan menggunakannya untuk menyimulasikan apa yang terjadi selanjutnya. Model ini jauh lebih efisien serta memiliki beberapa hasil yang mengesankan:
- Dreamer V2 adalah agen pertama yang mencapai performa tingkat manusia di Atari melalui model dunia.
- Dreamer V3 mengungguli metode khusus di lebih dari 150 tugas tanpa penyetelan khusus tugas.
- Dreamer 4 dilatih sepenuhnya dari data yang sudah dicatat sebelumnya, tanpa interaksi lingkungan hidup sama sekali.
JEPA (Joint Embedding Predictive Architecture dari Yann LeCun), memprediksi representasi abstrak alih-alih piksel. Model ini didasarkan pada gagasan bahwa pemahaman konseptual dan abstrak tentang dunia, alih-alih informasi visual mentah, lebih efektif untuk penalaran fisik. V-JEPA 2 mencapai 80 persen keberhasilan zero-shot pada tugas manipulasi hanya menggunakan video internet. LeCun mendukung pendekatan ini sedemikian rupa sehingga beliau mendirikan AMI Labs di Paris, yang mengumpulkan 1,03 miliar USD dengan valuasi 3,5 miliar USD, bahkan sebelum perusahaan tersebut mengirimkan satu produk.
Penalaran multimodal native adalah gagasan bahwa sistem AI perlu memproses teks, gambar, video, dan audio secara bersamaan dari bawah ke atas, bukan sebagai komponen terpisah yang disatukan. Empat arsitektur lainnya mengasumsikan bahwa Anda dapat mengambil sistem yang dibangun untuk teks serta menambahkan pemahaman fisik ke dalamnya. Penalaran multimodal native menolak hal ini, dengan alasan bahwa menambahkan pemahaman fisik ke sistem yang mengutamakan teks akan menciptakan batas yang sulit pada apa yang dapat dicapainya. Elorian, yang didirikan bersama oleh Andrew Dai dan Yinfei Yang sedang membangun tesis ini. Striker Partners memimpin putaran pendanaan bersama.
Model dunia berbasis difusi dapat berfungsi sebagai simulator pembelajaran tujuan umum, menghasilkan lingkungan yang akurat sepenuhnya dari dinamika. Model AI agentik DIAMOND mencapai skor normalisasi manusia tertinggi dari setiap model dunia di Atari 100k. UniSim menunjukkan bahwa model berbasis satu difusi dapat menyimulasikan bagaimana manusia dan robot berinteraksi dengan dunia fisik. Dari lima arsitektur tersebut, model berbasis difusi adalah yang paling sedikit diuji dalam robotik dunia nyata.
Belum jelas apakah satu paradigma akan mendominasi atau apakah kelima paradigma tersebut akan secara bertahap bergabung menjadi sesuatu yang baru. Bukti dari 18 bulan terakhir menunjukkan hibridisasi. Pemahaman fisik muncul di kelima arsitektur saat mereka berskala, dan kesenjangan di antara masing-masing arsitektur makin menyempit. Ketika ini terjadi, pembeda terbesar mungkin bukan terletak pada arsitektural, hal ini mungkin bergantung pada tim mana yang dapat mengubah penelitian menjadi produksi paling cepat.
Skala berfungsi. Ekonomi tidak.
Bidang ini berkembang dengan pesat. Parameter model dunia telah bertambah sekitar seribu kali lipat dalam lima tahun, dari dua juta PlaNet hingga 14 miliar Cosmos. Proses pelatihan sekarang menyaingi upaya model bahasa terbesar: Cosmos mengonsumsi 10.000 GPU H100 selama tiga bulan. Pada skala ini, sesuatu yang menarik mulai terjadi.
Pemahaman tentang dunia fisik mulai muncul sebagai efek samping yang tidak disengaja dari menskalakan. Model tidak diprogram untuk memahami sebab-akibat di dunia fisik, alih-alih, mereka menyelesaikannya sendiri. OpenAI mengamati ini di Sora, misalnya, sebagai konsistensi 3D, permanensi objek, dan fisika realistis muncul sebagai hasil properti dari mengurangi skala (scale in) dalam model. DeepMind mengamati hal yang sama di Genie 2 pada 11 miliar parameter. Pola yang sama berlaku di setiap arsitektur, sehingga sulit untuk menganggapnya sebagai kebetulan belaka.
Beberapa pemain besar belum lama ini memilih untuk merilis model mereka secara publik alih-alih merahasiakannya. Cosmos dari NVIDIA, V-JEPA 2 dari Meta, dan pi-zero dari Physical Intelligence semuanya bersumber terbuka pada tahun 2025. Dalam bidang yang kompetitif, ini merupakan pertanda yang jelas, menunjukkan bahwa berkontribusi pada komunitas penelitian yang luas menjadi strategi yang lebih baik untuk kemajuan alih-alih merahasiakannya.
Namun, meskipun kemampuan model telah meningkat, biaya menjalankannya belum. Model bahasa teks berharga sekitar lima belas sen per seratus jam pengguna. Biaya Sora 468 USD per jam pengguna. Bahkan Odyssey, salah satu opsi yang lebih efisien, masih membutuhkan H100 khusus per sesi pada 50 USD per jam. Alasannya struktural, karena video harus dihasilkan terus menerus, secara waktu nyata, bingkai demi bingkai. Anda tidak dapat menyebarkan 50 pengguna di satu GPU seperti yang dapat dilakukan model teks, yang berarti ekonomi unit lebih dekat dengan komputasi cloud premium dibandingkan harga API.
Kesenjangan ini, antara apa yang dapat dilakukan model dalam penelitian dan berapa biaya untuk menjalankannya, adalah hambatan terbesar antara hasil lab dan deployment dunia nyata. Kabar baiknya? Kami pernah melihat kurva biaya semacam ini sebelumnya. Biaya inferensi LLM turun kira-kira seribu kali lipat dalam tiga tahun, serta Decart sudah mengklaim pengurangan biaya 400x untuk video melalui mesin yang dibuat khusus. Sistem inferensi tingkat produksi yang akan memberikan ini dalam skala besar belum ada sebagai produk komersial. Dengan demikian, tim yang pertama kali membangunnya akan mendapatkan keunggulan kompetitif yang kuat.
NVIDIA telah merakit tumpukan infrastruktur yang paling terintegrasi secara vertikal di ruang ini: Cosmos untuk pelatihan model dunia, Isaac Sim untuk simulasi fisika, GR00T untuk model fondasi humanoid, Omniverse untuk kembaran digital, dan Jetson Thor untuk inferensi VLA edge. AWS menyediakan lapisan cloud tempat semua ini dilatih dan di-deploy: Amazon SageMaker untuk pelatihan model, AWS Batch untuk simulasi skala besar serta orkestrasi beban kerja, AWS Inferentia untuk inferensi yang dioptimalkan, dan AWS IoT Greengrass untuk manajemen armada edge. Dalam produksi, polanya konsisten: NVIDIA untuk fidelitas fisika, cloud untuk pelatihan dan orkestrasi data, silikon yang dibuat khusus untuk deployment secara waktu nyata.
Tiga kesenjangan yang menentukan lini masa
Tantangan infrastruktur bukan satu-satunya hal yang menghalangi penelitian dan deployment komersial. Ada tiga kesenjangan struktural yang lebih dalam yang akan menentukan seberapa cepat transisi ini terjadi.
1. Kesenjangan data
Hal pertama adalah kesenjangan yang tidak dapat ditutup oleh jumlah video. Video mengambil bagaimana sesuatu terlihat, bukan bagaimana rasanya. Tugas yang melibatkan sentuhan, seperti menangani material, memasukkan komponen atau merakit bagian, mengakibatkan penurunan performa model dari mengesankan menjadi tidak dapat digunakan. Mengapa? Tidak ada informasi taktil dalam data pelatihan. Bayangkan bahwa tangan manusia mengandung 17.000 reseptor sentuhan. Sebagian besar tangan robot yang di-deploy, di sisi lain, tidak memiliki sensor taktil. Meskipun sensor itu sendiri tersedia, saat ini belum ada set data taktil terstandardisasi yang ada dalam skala besar. Ini bukan kegagalan pendanaan atau teknologi, melainkan kegagalan koordinasi. Setiap laboratorium akan mendapat manfaat dari set data seperti itu, tetapi tidak ada yang memiliki insentif yang cukup untuk membangunnya sendiri. Siapa pun yang memecahkan masalah koordinasi ini, baik melalui konsorsium terbuka maupun permainan data komersial, akan mempercepat seluruh bidang ini dengan besaran yang sulit untuk dilebih-lebihkan.
2. Kesenjangan arsitektural
Sebagian besar perusahaan robotik saat ini mengandalkan pembelajaran imitasi: mendemonstrasikan tugas, lalu robot mereplikasinya. Ini berfungsi untuk tugas sederhana tetapi kesulitan dalam kondisi yang tidak dapat diprediksi. Ketika GRASP Lab dari UPenn menguji robot yang dilatih dengan cara ini dalam kondisi yang benar-benar baru, GRASP Lab mencatat tingkat keberhasilan hanya 16,7 persen, yang jauh dari keandalan yang dibutuhkan oleh kondisi dunia nyata.
Model dunia menawarkan pendekatan yang berbeda. Robot dapat mengeksplorasi mode kegagalan dalam simulasi, mengulangi kasus edge tanpa risiko fisik, dan membangun kompetensi sebelum di-deploy di dunia nyata. Setiap kasus yang terdokumentasi tentang robot yang beroperasi terus menerus selama 10 jam atau lebih tanpa campur tangan manusia telah menggunakan pembelajaran penguatan ini, bukan pembelajaran imitasi. Untuk mencapai keandalan tingkat industri, kami perlu bergerak melampaui imitasi sederhana menuju metode pembelajaran yang lebih kuat.
3. Koherensi temporal
Model dunia video-generatif dapat menyimulasikan fisika yang meyakinkan dalam waktu singkat. Namun, jika dijalankan dalam jangka waktu yang lebih lama, model tersebut mulai menjadi tidak konsisten. Objek mungkin berakhir di tempat yang salah atau sesuatu yang seharusnya tidak menyebabkan reaksi. Makin lama simulasi berjalan, makin banyak kesalahan dapat terbentuk, sampai dunia simulasi tidak lagi menyerupai dunia fisik. Genie 3, misalnya, koheren hanya beberapa menit sebelum pergeseran semacam ini terjadi. Ini adalah masalah yang dibuat ke dalam bagaimana model ini dirancang, jadi membutuhkan solusi arsitektural. Model lain, seperti Marble dari World Labs, dapat menangani pergeseran temporal dengan lebih baik, tetapi model ini cenderung lebih mahal. Oleh karena itu, tantangan sebenarnya terletak pada temuan keseimbangan yang tepat antara simulasi dengan fidelitas tinggi dan biaya menjalankannya.
Memetakan ekosistem
Kami memetakan lebih dari 120 entitas di seluruh model dunia dan ekosistem AI multimodal. Visualisasi jaringan interaktif lengkap disertakan bersama dokumen ini.
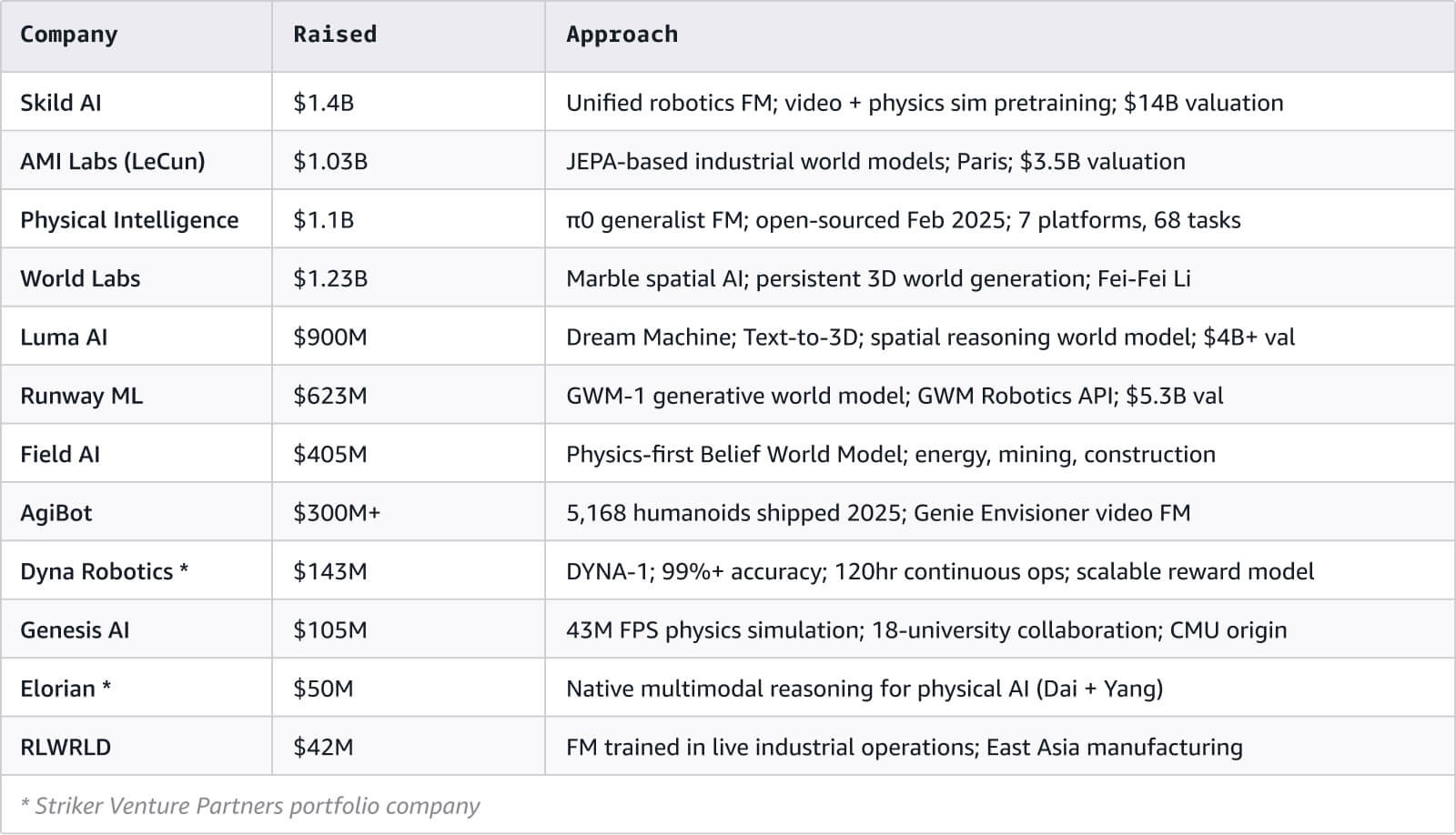
Banyak orang di belakang perusahaan-perusahaan ini adalah para peneliti, bukan manajer produk, dan telah meninggalkan bidang akademis untuk bergabung dengan merek teknologi besar. Hafner dan Yan pindah dari seri Dreamer ke Embo, Hausman meninggalkan tim robotik DeepMind untuk ikut mendirikan Physical Intelligence, LeCun pindah dari Meta AI ke AMI Labs.
Kesediaan para peneliti tersebut meninggalkan peran tetap mereka dan laboratorium penelitian perusahaan untuk mengomersialkan ilmu yang mereka kembangkan menandakan perubahan besar. Ilmu inti telah matang melewati titik pengembalian pada makalah berikutnya yang melebihi pengembalian produk pertama.
Seberapa cepat dan siapa yang mendapat nilai?
Setiap transisi besar dalam machine learning mengikuti pola yang sama, pola yang begitu konsisten sehingga lebih menyerupai hukum alam alih-alih tren. Representasi yang dipelajari menggantikan representasi yang direkayasa secara manual. Setiap kali AI menemukan cara untuk mempelajari sesuatu secara otomatis dari data, ia menggantikan pendekatan lama manusia yang melakukan enkode aturan secara manual, dan itu terjadi secara cepat. Transformator melakukannya untuk aturan tata bahasa yang dikode secara manual dan model dunia sekarang mencoba hal yang sama untuk fisika itu sendiri, menggantikan simulator yang dibuat secara manual dengan model yang dipelajari yang dilatih pada video skala internet.
Pertanyaannya sekarang bukan pada apakah hal itu terjadi secara prinsip, tetapi seberapa cepat hal itu terjadi, tantangan mana yang diselesaikan terlebih dahulu, dan siapa yang mendapatkan nilai jangka panjang.
Penskalaan jelas dan konsisten di seluruh arsitektur dan ekonomi data meningkat. Biaya inferensi masih tinggi tetapi turun, karena kombinasi desain model yang lebih efisien, infrastruktur pelayanan yang lebih baik, serta deployment perangkat keras inferensi khusus yang cepat.
Selain itu, banyak modal yang mendukung pasar ini: lebih dari 3 miliar USD telah terkumpul di berbagai startups model fondasi terkemuka, dan perusahaan yang membangun perangkat keras humanoid, secara agregat, bernilai lebih dari 50 miliar USD.
Lapisan terpenting, dan yang paling kurang berkembang, adalah infrastruktur yang menghubungkan model terlatih ke deployment dunia nyata: peralatan, mesin penyajian, dan sistem manajemen armada. Perusahaan serta pendiri yang membangun solusi ini akan menempati posisi yang sama dengan penyedia cloud seperti AWS di dunia model bahasa: menyediakan lapisan penting yang pada akhirnya menjadi dasar dari segala hal lainnya.

Nikhil Suresh
Nikhil Suresh adalah seorang investor di Striker Venture Partners, beliau berpartner dengan para pendiri sejak awal untuk membangun perusahaan yang mendefinisikan kategori di sektor AI, infrastruktur, dan perangkat keras. Seorang mantan pendiri serial serta peneliti AI di Scaling Intelligence Lab Stanford, Nikhil sebelumnya adalah seorang rekayasawan awal di Mercor yang bekerja di Search dan ML. Nikhil berfokus pada membantu tim berpotensi tinggi menavigasi pembentukan produk tahap awal untuk membangun bisnis yang generasional dan berdaya tahan .

Dhruv Sharma
Dhruv Sharma adalah anggota dari tim Venture Capital & Startups di AWS, beliau berpartner dengan perusahaan modal ventura terkemuka dan perusahaan portofolio mereka untuk membangun, meluncurkan, dan menskalakan – khususnya di sektor infrastruktur AI serta teknologi terdepan. Sebelumnya, beliau menghabiskan lebih dari delapan tahun di modal ventura dan perbankan investasi, memimpin investasi dan membantu menskalakan perusahaan dari tahap awal hingga IPO.
Bagaimana konten ini?