- Produto
- Machine Learning
- AWS Trainium
AWS Trainium
Trainium — projetado especificamente para IA de alto desempenho e custo eficiente em escala
Por que usar o Trainium?
O AWS Trainium é uma família de aceleradores de IA com propósito específico (Trainium1, Trainium2 e Trainium3) e projetados para oferecer desempenho escalável e eficiência de custos para treinamento e inferência em uma ampla variedade de workloads de IA generativa
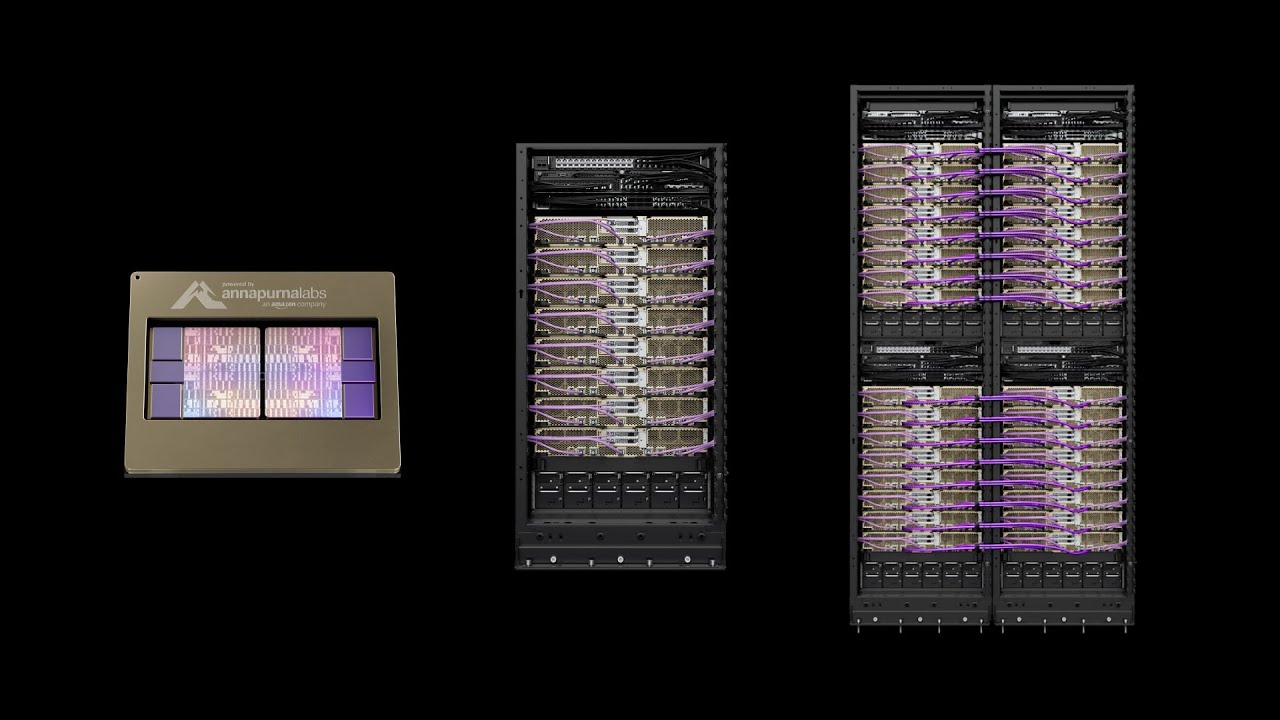
A família do AWS Trainium
Trainium1
O chip do AWS Trainium de primeira geração é responsável pelas instâncias Trn1 do Amazon Elastic Compute Cloud (Amazon EC2), que apresentam custos de treinamento até 50% menores do que as instâncias comparáveis do Amazon EC2. Muitos clientes, incluindo a Ricoh, a Karakuri, a SplashMusic e a Arcee AI, estão percebendo os benefícios de desempenho e custos das instâncias Trn1.
Trainium2
O chip do AWS Trainium2 proporciona um desempenho até 4 vezes superior quando comparado ao chip do Trainium de primeira geração. As instâncias Trn2 do Amazon EC2 e os UltraServers Trn2 baseados no Trainium2 foram desenvolvidas com propósito específico para IA generativa e oferecem um custo-benefício de 30 a 40% melhor em comparação com as instâncias EC2 P5e e P5en baseadas em GPU. As instâncias Trn2 apresentam até 16 chips Trainium2 e os UltraServers Trn2 apresentam até 64 chips Trainium2 interconectados com o NeuronLink, nossa interconexão exclusiva entre chips. É possível usar as instâncias Trn2 e o UltraServers para treinar e implantar modelos mais complexos, incluindo grandes modelos de linguagem (LLMs), modelos multimodais e transformadores de difusão, para o desenvolvimento de uma ampla variedade de aplicações de IA generativa da próxima geração.
Trainium3
O 3nm, nosso primeiro chip de IA da AWS, foi desenvolvido especificamente para oferecer a melhor economia de tokens para aplicações agênticas, de raciocínio e de geração de vídeo de próxima geração. O chip AWS Trainium3 oferece desempenho computacional duas vezes maior para 2,52 petaflops (PFLOPs) de computação FP8, aumenta a capacidade de memória em 1,5 vez e a largura de banda em 1,7 vez em relação ao Trainium2 para 144 GB de memória HBM3e e 4,9 TB/s de largura de banda de memória. Os Trn3 UltraServers, equipados com Trainium3, oferecem desempenho até 4,4 vezes maior, largura de banda de memória 3,9 vezes maior e eficiência energética mais de 4 vezes melhor em comparação com os Trn2 UltraServers. O Trainium3 foi projetado para workloads paralelas densas e especializadas com tipos de dados avançados (MXFP8 e MXFP4). Além disso, oferece melhor equilíbrio entre memória e computação em tarefas de raciocínio, multimodais e em tempo real.
Criado para desenvolvedores
Os novos UltraServers baseados em Trainium3 foram criados para pesquisadores de IA e desenvolvidos pelo AWS Neuron SDK para alcançar um desempenho sem precedentes.
Com a integração nativa com o PyTorch, os desenvolvedores podem realizar o treinamento e a implantação sem alterar uma única linha de código. Para engenheiros de desempenho de IA, possibilitamos um acesso mais profundo ao Trainium3, para que os desenvolvedores possam ajustar o desempenho, personalizar os kernels e aprimorar ainda mais seus modelos. Como a abertura promove a inovação, temos o compromisso de interagir com nossos desenvolvedores por meio de ferramentas e recursos de código aberto.
Para saber mais, acesse o Amazon EC2 Trn3 UltraServers e explore o AWS Neuron SDK.
Benefícios
Os Trn3 UltraServers apresentam as mais recentes inovações na tecnologia UltraServer de escalabilidade, com o NeuronSwitch-v1 para coletivos all-to-all mais rápidos em até 144 chips Trainium3. O Trn3 UltraServer fornece até 20,7 TB de HBM3e, 706 TB/s de largura de banda de memória e 362 PFLOPs MXFP8, oferecendo até 4,4 vezes mais desempenho e mais de 4 vezes melhor eficiência energética do que os Trn2 UltraServers. O Trn3 oferece o mais alto desempenho ao menor custo para treinamento e inferência com os mais recentes modelos de raciocínio e MoE de mais de 1 trilhão de parâmetros, e gera um throughput significativamente maior para o GPT-OSS servindo em grande escala em comparação com as instâncias baseadas em Trainium2.
Os Trn2 UltraServers continuam sendo uma opção econômica e de alto desempenho para treinamento de IA generativa e inferência de modelos de até 1 trilhão de parâmetros. As instâncias Trn2 apresentam até 16 chips Trainium2, e os Trn2 UltraServers apresentam até 64 chips Trainium2 conectados ao NeuronLink, uma interconexão de chip a chip proprietária.
As instâncias Trn1 apresentam até 16 chips Trainium e oferecem até 3 PFLOPs FP8, 512 GB de HBM com 9,8 TB/s de largura de banda de memória e até 1,6 Tbps de rede EFA.
O AWS Neuron SDK ajuda você a extrair todo o desempenho das instâncias Trn3, Trn2 e Trn1, permitindo que você se concentre no desenvolvimento e na implantação de modelos, acelerando o tempo de lançamento no mercado. O AWS Neuron fornece integração nativa com o PyTorch Jax e bibliotecas fundamentais, como Hugging Face, vLLM, PyTorch Lightning, entre outras. Ele otimiza os modelos automaticamente para treinamento e inferência distribuídos, ao mesmo tempo em que oferece insights aprofundados para criação de perfis e depuração. O AWS Neuron se integra com serviços como o Amazon SageMaker, Amazon SageMaker Hyerpod, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), AWS ParallelCluster e AWS Batch, bem como com serviços de entidades externas, como Ray (Anyscale), Domino Data Lab e Datadog.
Para oferecer alto desempenho e, ao mesmo tempo, cumprir metas de precisão, o AWS Trainium é compatível com uma variedade de opções de
tipos de dados de precisão mista, como BF16, FP16, FP8, MXFP8 e MXFP4. Para atender ao ritmo acelerado da inovação em IA generativa,
o Trainium2 e o Trainium3 apresentam otimizações de hardware para 4 vezes mais dispersão (16:4), microajuste de escala,arredondamento
estocástico e mecanismos coletivos dedicados.
O Neuron permite que os desenvolvedores otimizem as workloads usando a Neuron Kernel Interface (NKI) para o desenvolvimento do kernel. O NKI expõe o Trainium ISA completo, permitindo controle total sobre programação em nível de instrução, alocação de memória e programação de execução. Além de criar os próprios kernels, os desenvolvedores podem usar a Neuron Kernel Library, que são kernels de código aberto otimizados, prontos para implantação. E, por fim, o Neuron Explore oferece visibilidade total da pilha, conectando o código dos desenvolvedores aos mecanismos do hardware.
Clientes
Clientes como Anthropic, Decart, poolside, Databricks, Ricoh, Karakuri, SplashMusic e outros estão obtendo benefícios de desempenho e custo das instâncias Trn1, Trn2 e Trn3 e dos UltraServers.
Os primeiros usuários das instâncias Trn3 estão alcançando novos níveis de eficiência e escalabilidade para a próxima geração de modelos de IA generativa em grande escala.

Conquiste a performance, o custo e a escala da IA

AWS Trainium2 para performance inovadora da IA

Histórias de clientes de chips de IA da AWS

