- Producto
- Machine Learning
- AWS Trainium
AWS Trainium
Trainium: diseñado específicamente para una IA rentable y de alto rendimiento a escala
¿Por qué Trainium?
AWS Trainium es una familia de aceleradores de IA desarrollados de manera específica (Trainium1, Trainium2 y Trainium3) diseñados con el objetivo de ofrecer rendimiento escalable y rentabilidad para el entrenamiento y la inferencia en una amplia gama de cargas de trabajo de IA generativa
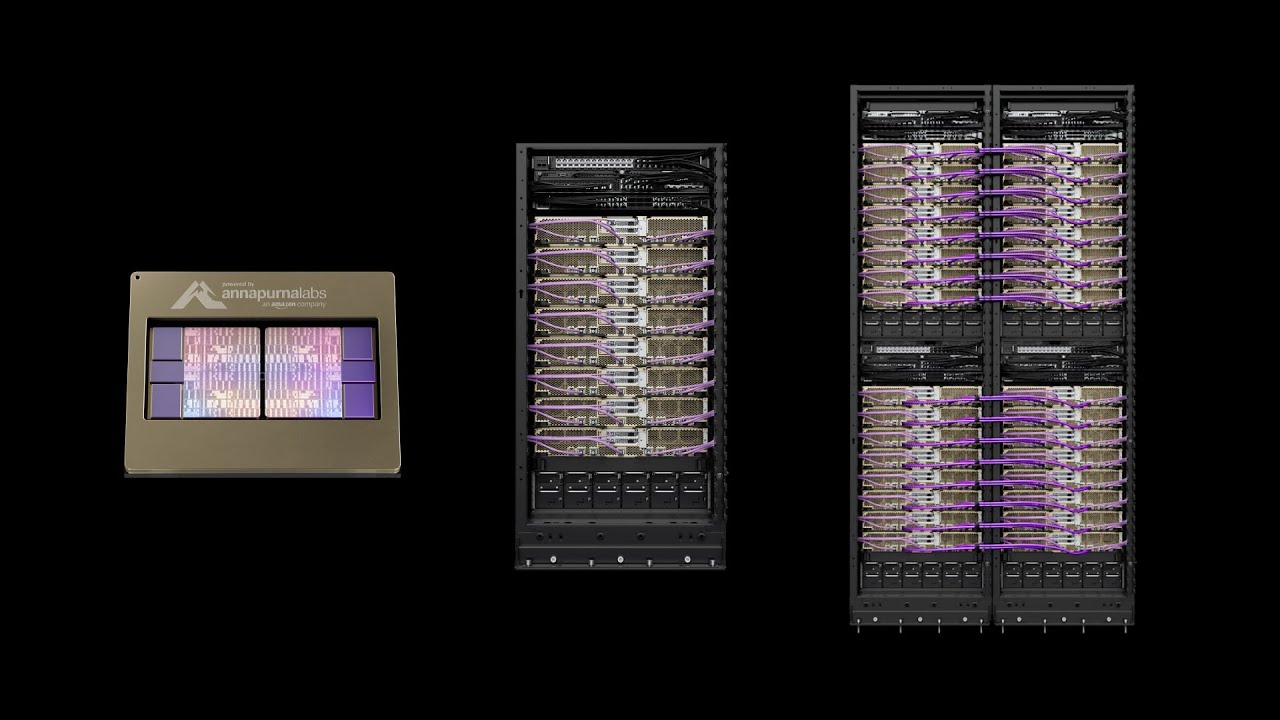
La familia AWS Trainium
Trainium1
El chip AWS Trainium de primera generación impulsa las instancias Trn1 de Amazon Elastic Compute Cloud (Amazon EC2), que tienen costos de entrenamiento hasta un 50 % más bajos que las instancias de Amazon EC2 similares. Muchos clientes, como Ricoh, Karakuri, SplashMusic y Arcee AI, se están dando cuenta de los beneficios de rendimiento y costo de las instancias Trn1.
Trainium2
El chip AWS Trainium2 ofrece hasta cuatro veces más de rendimiento que el Trainium de primera generación. Las instancias Trn2 de Amazon EC2 y Trn2 UltraServers basadas en Trainium2 están diseñadas de manera específica para la IA generativa y ofrecen una relación precio-rendimiento entre un 30 y un 40 % superior a las instancias P5e y P5en de EC2 basadas en GPU. Las instancias Trn2 cuentan con hasta 16 chips Trainium2, mientras que las Trn2 UltraServers cuentan con hasta 64 chips Trainium2 interconectados con NeuronLink, nuestra interconexión exclusiva de chip a chip. Puede usar las instancias Trn2 y UltraServers para entrenar e implementar los modelos más exigentes, incluidos modelos de lenguaje de gran tamaño (LLM), modelos multimodales y transformadores de difusión, con el fin de crear un amplio conjunto de aplicaciones de IA generativa de última generación.
Trainium3
El primer chip de IA de AWS de 3 nm está diseñado específicamente para ofrecer la mejor economía de tokens en aplicaciones de generación de video, razonamiento y agénticas de última generación. El chip AWS Trainium3 proporciona un rendimiento de cómputo 2 veces superior a 2,52 petaflops (PFLOP) de procesamiento FP8, aumenta la capacidad de memoria en 1,5 veces y el ancho de banda en 1,7 veces más que Trainium2 hasta 144 GB de memoria HBM3e y 4,9 TB/s de ancho de banda de memoria. Los servidores Trn3 UltraServer, con tecnología Trainium3, ofrecen un rendimiento hasta 4,4 veces mayor, un ancho de banda de memoria 3,9 veces mayor y una eficiencia energética 4 veces mayor en comparación con los servidores Trn2 UltraServer. Trainium3 está diseñado para cargas de trabajo densas y paralelas para expertos con tipos de datos avanzados (MXFP8 y MXFP4) y un equilibrio mejorado entre la memoria y el procesamiento para tareas de razonamiento, multimodales y en tiempo real.
Creado para desarrolladores
Los nuevos servidores UltraServers basados en Trainium3 están diseñados para los investigadores de IA y se basan en el SDK de AWS Neuron, para lograr un rendimiento sin precedentes.
Con la integración nativa de PyTorch, los desarrolladores pueden entrenar e implementar sin cambiar ni una sola línea de código. Para los ingenieros de rendimiento de IA, hemos permitido un acceso más profundo a Trainium3, de modo que los desarrolladores puedan refinar el rendimiento, personalizar los núcleos y llevar sus modelos aún más lejos. Dado que la innovación se nutre de la apertura, nos comprometemos a interactuar con nuestros desarrolladores a través de herramientas y recursos de código abierto.
Para obtener más información, visite Amazon EC2 Trn3 UltraServers y explore SDK de AWS Neuron.
Beneficios
Los servidores Trn3 UltraServers cuentan con las últimas innovaciones en la tecnología UltraServer de escalado vertical, con NeuronSwitch-v1 para colectivos más rápidos e integrales en hasta 144 chips Trainium3. Trn3 UltraServer proporciona hasta 20,7 TB de HBM3e, 706 TB/s de ancho de banda de memoria y 362 PFLOPs MXFP8, lo que proporciona hasta 4,4 veces más rendimiento y más de 4 veces más eficiencia energética que los Trn2 UltraServers. Trn3 proporciona el rendimiento más alto al menor costo de entrenamiento e inferencia con los modelos más recientes de MoE y de razonamiento con más de 1 billón de parámetros, y ofrece un rendimiento significativamente mayor para GPT-OSS a escala en comparación con las instancias basadas en Trainium2.
Las instancias Trn2 UltraServers siguen siendo una opción rentable y de alto rendimiento para el entrenamiento de la IA generativa y la inferencia de modelos con hasta 1 billón de parámetros. Las instancias Trn2 cuentan con hasta 16 chips Trainium2, mientras que las Trn2 UltraServers cuentan con hasta 64 chips Trainium2 conectados con NeuronLink, una interconexión exclusiva de chip a chip.
Las instancias Trn1 cuentan con hasta 16 chips Trainium y ofrecen hasta 3 PFLOP FP8, 512 GB de HBM con 9,8 TB/s de ancho de banda de memoria y hasta 1,6 Tbps de redes EFA.
El SDK de AWS Neuron le permite sacar el máximo rendimiento de las instancias Trn3, Trn2 y Trn1 para que pueda centrarse en crear e implementar modelos y acelerar el tiempo de comercialización. AWS Neuron se integra de forma nativa con PyTorch, Jax y bibliotecas esenciales como Hugging Face, vLLM o PyTorch Lightning, entre otras. Optimiza los modelos listos para usar de cara al entrenamiento y a la inferencia distribuidos, al mismo tiempo que proporciona información detallada destinada a la creación de perfiles y a la depuración. AWS Neuron se integra con servicios como Amazon SageMaker, Amazon SageMaker Hyperpod, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), AWS ParallelCluster y AWS Batch, así como con servicios de terceros como Ray (Anyscale), Domino Data Lab y Datadog.
A fin de ofrecer un alto rendimiento y, al mismo tiempo, cumplir con los objetivos de precisión, AWS Trainium admite diferentes tipos de datos
de precisión mixta como BF16, FP16, FP8, MXFP8 y MXFP4. Para respaldar el rápido ritmo de la innovación en IA generativa,
Trainium2 y Trainium3 incluyen optimizaciones de hardware para una dispersión 4 veces mayor (16:4), microescalado, redondeo
estocástico y motores colectivos dedicados.
Neuron permite a los desarrolladores optimizar sus cargas de trabajo mediante Neuron Kernel Interface (NKI) para el desarrollo del kernels. NKI expone el ISA completo de Trainium, lo que permite un control total sobre la programación a nivel de instrucción, la asignación de memoria y la programación de la ejecución. Además de crear sus propios kernels, los desarrolladores pueden usar Neuron Kernel Library, que es de código abierto y está lista para la implementación de núcleos optimizados. Por último, Neuron Explore proporciona una visibilidad de full stack, al conectar el código de los desarrolladores con los motores del hardware.
Clientes
Clientes como Anthropic, Decart, Poolside, Databricks, Ricoh, Karakuri, SplashMusic y otros están obteniendo los beneficios de rendimiento y costo de las instancias y los servidores UltraServer Trn1, Trn2 y Trn3.
Los primeros usuarios de Trn3 están logrando nuevos niveles de eficiencia y escalabilidad en la próxima generación de modelos de IA generativa a gran escala.

Conquiste el rendimiento, el coste y la escala de la IA

AWS Trainium2, diseñado para que la IA rinda como nunca

Historias de clientes con los chips de IA de AWS

